AI assistants status overview
Out of the many questions we get from our users, many concerns the status and training of our AI assistant models. We’re the first to admit this has been a bit of a black box, with users asking us questions like:
- When will my model train next?
- What are the ML metrics for my model?
- How is my model improving?
Now, you can answer these questions yourself. With our new AI assistants status page, you can see how models improve over time to get an idea of how you are progressing towards annotation automation.
Where to find it
Click on the project card. Then you should land on the following page for the project.
On the left-hand sidebar, you can find "AI-Assistant status" under "Tools".
Click on the AI-Assistant status.
You can now see how your models are performing and changing over time.
What you can see
With our new AI assistants status page, you can see how models improve over time to get an idea of how you are progressing towards annotation automation. Every potential model available in Hasty is displayed here. If a model has been successfully trained you will see this:
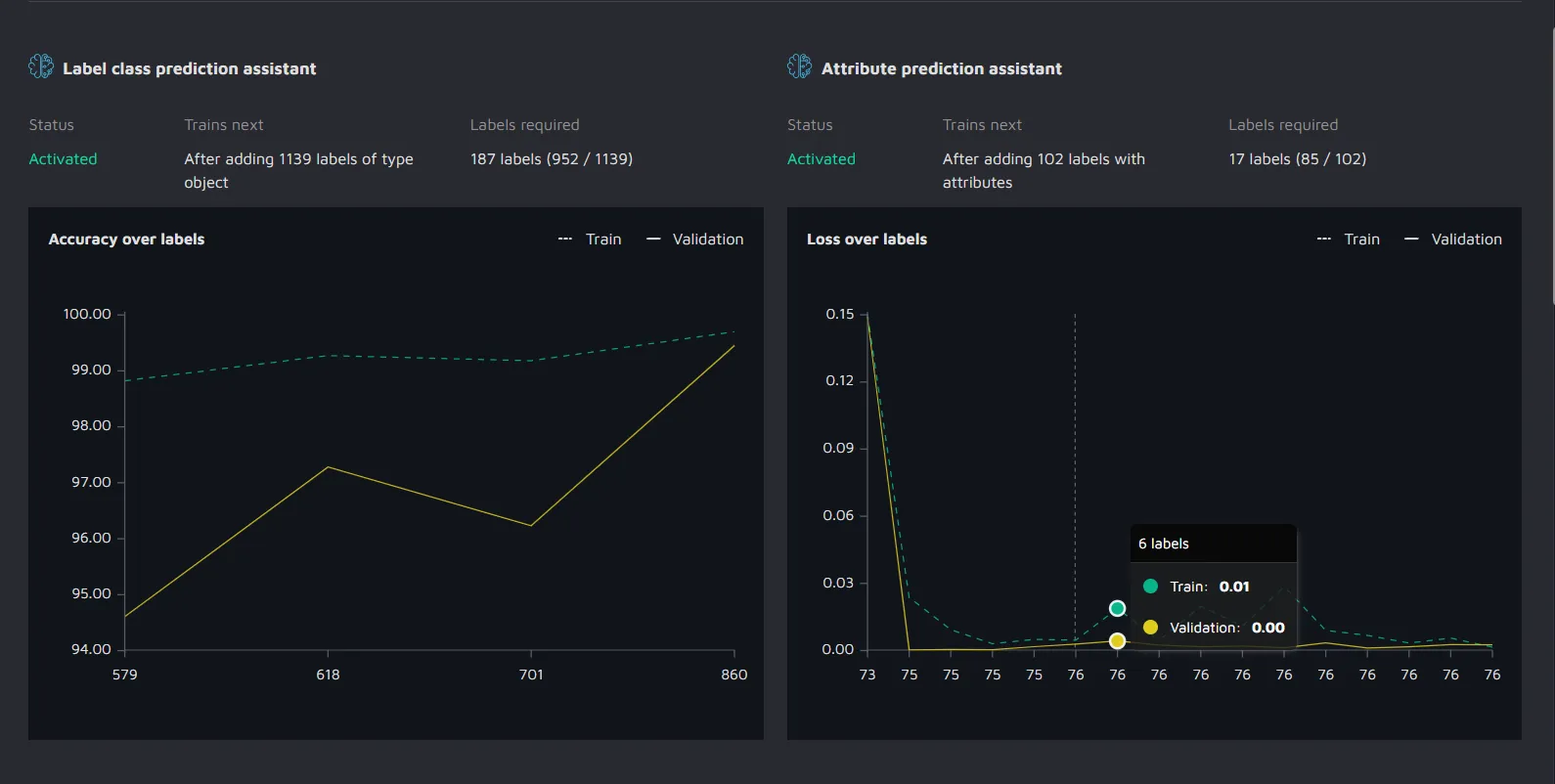
There are four pieces of important information:
- The status of the model - is it activated, training (activated but with a new model in the works), failed (you shouldn't see this - if you do, contact us), or not activated (not enough data yet)
- Next, you see the Trains next section. This tells you how many new annotations or images you need to annotate to train a new model (differs depending on model)
- Then, we have the Labels required section. This shows you how close you are to triggering the training of a new model
- Finally, we have our graph that shows you how your model improves over time
How to use it
We hope that this new visibility into how models perform in Hasty can be used to better understand what's going on behind the scenes and how automation improves over time.
What's important to know here, is that you might not see a gradual improvement from the start. Machine learning models are fickle beasts and often take some time to become accurate.
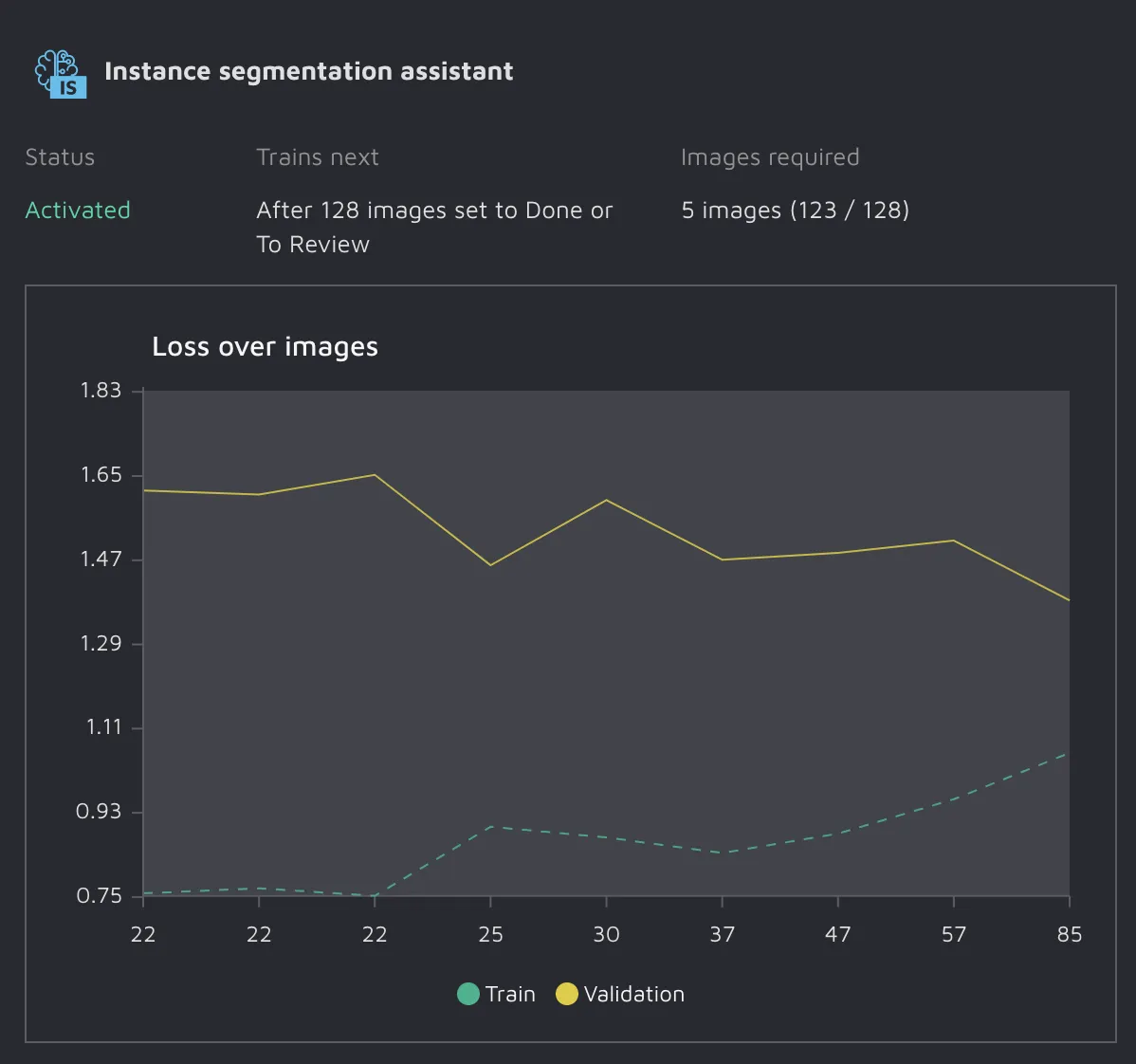
Here's an example from an internal demo project we did for a customer demo. What we see is the training loss starting very low with our validation loss being much higher. As we continued to annotate, we got the two metrics converging closer to each other, indicating a better-performing model.