Creating a new split
Before running experiments in Model Playground, you need to create a split.
To do so, please access Model Playground in the burger menu on the left and click the Create split button.
Parameters used for creating a new split
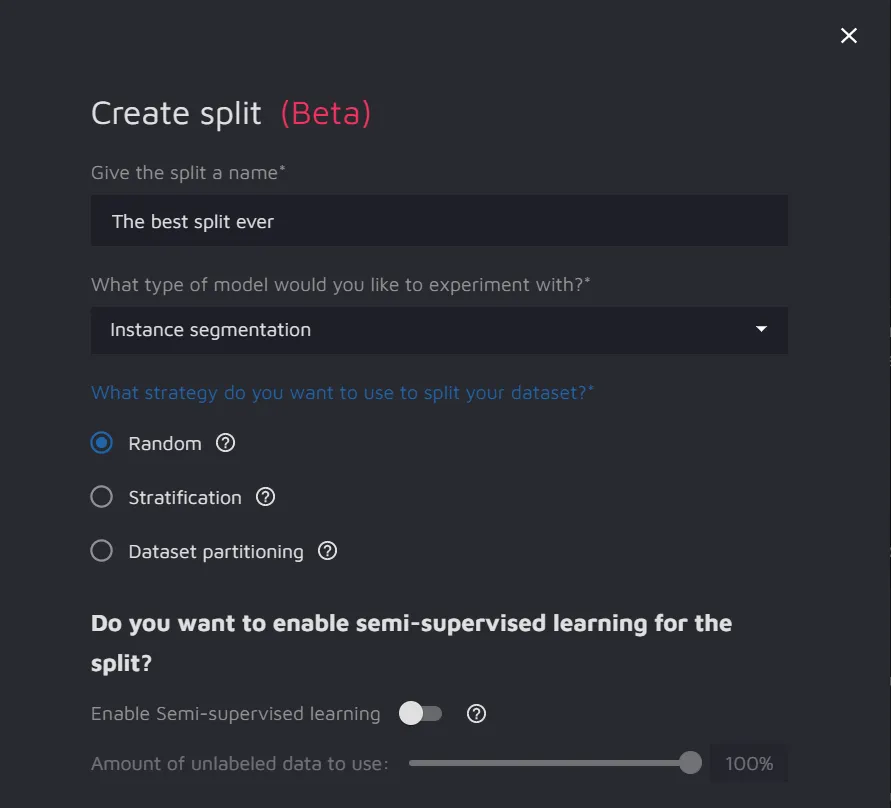
- Split name;
- Type of model you would like to experiment with - the list includes:
- Split strategy - a strategy used to divide your dataset. The list includes:
- Random sampling - the data is randomly allocated to the Test, Train, and Validation sets according to the specified proportions. One data point is assigned only to one set without repetition;
- Stratification - this strategy preserves the proportion of each label in each set. It may be helpful if the dataset has a class imbalance.
- Dataset partitioning - allows to assign each dataset to a particular partition. When selecting less than 100%, the algorithm will randomly sample the data from the selected datasets. Dataset partitioning is appropriate when you have already performed the data split and uploaded the partitions in separate datasets.
- Semi-Supervised Learning - this feature is available for Object Detection and Instance Segmentation tasks. Toggle it on to enable the feature.
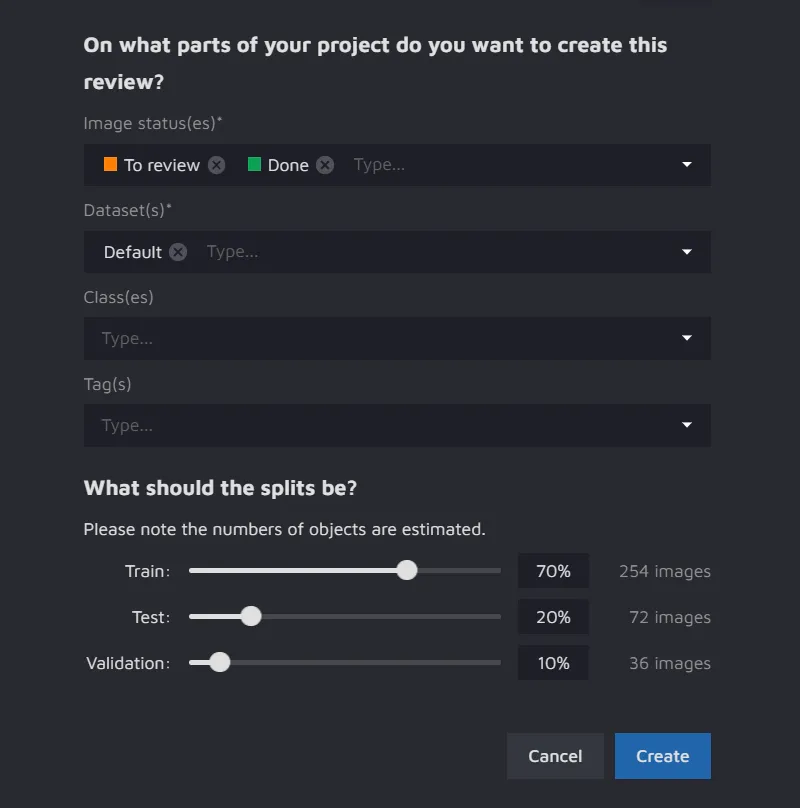
- Part of a project to be used for split creation:
- Image Statuses - select the files based on their status;
- Datasets - select the datasets required for your experiment;
- Classes - include particular classes in the split (optional);
- Tags - include particular tags in the split (optional).
- Split percentage ratio - tweak the percentage of images to be divided into the Train, Test, and Validation datasets. The default percentages for the Train, Test, and Validation datasets are 70%, 20%, and 10%, respectively.