Object Detection
Computer Vision (CV) is a scientific field that researches software systems trained to extract information from visual data, analyze it, and draw conclusions based on the analysis. The area consists of so-called CV or vision AI tasks. Each task is unique and incorporates techniques and heuristics for acquiring, processing, analyzing, and understanding the data and extracting various details from it. One of these tasks is Object Detection. On this page, we will:
- Understand the basics of the Object Detection field in Machine Learning;
- Cover in-depth the Object Detection vision AI task;
- See how Object Detection compares with Object Localization;
- Research the real-life applications of Object Detection;
- Cover some popular Object Detection datasets and SOTA results on them;
- See features that CloudFactory uses for streamlining an Object Detection task.
Let’s jump in.
What is Object Detection in Machine Learning?
Object Detection (OD) is a Computer Vision Supervised Learning task that aims to locate and classify every object of the target classes presented in an image. So, you can view OD as a combination of Localization and Classification tasks.
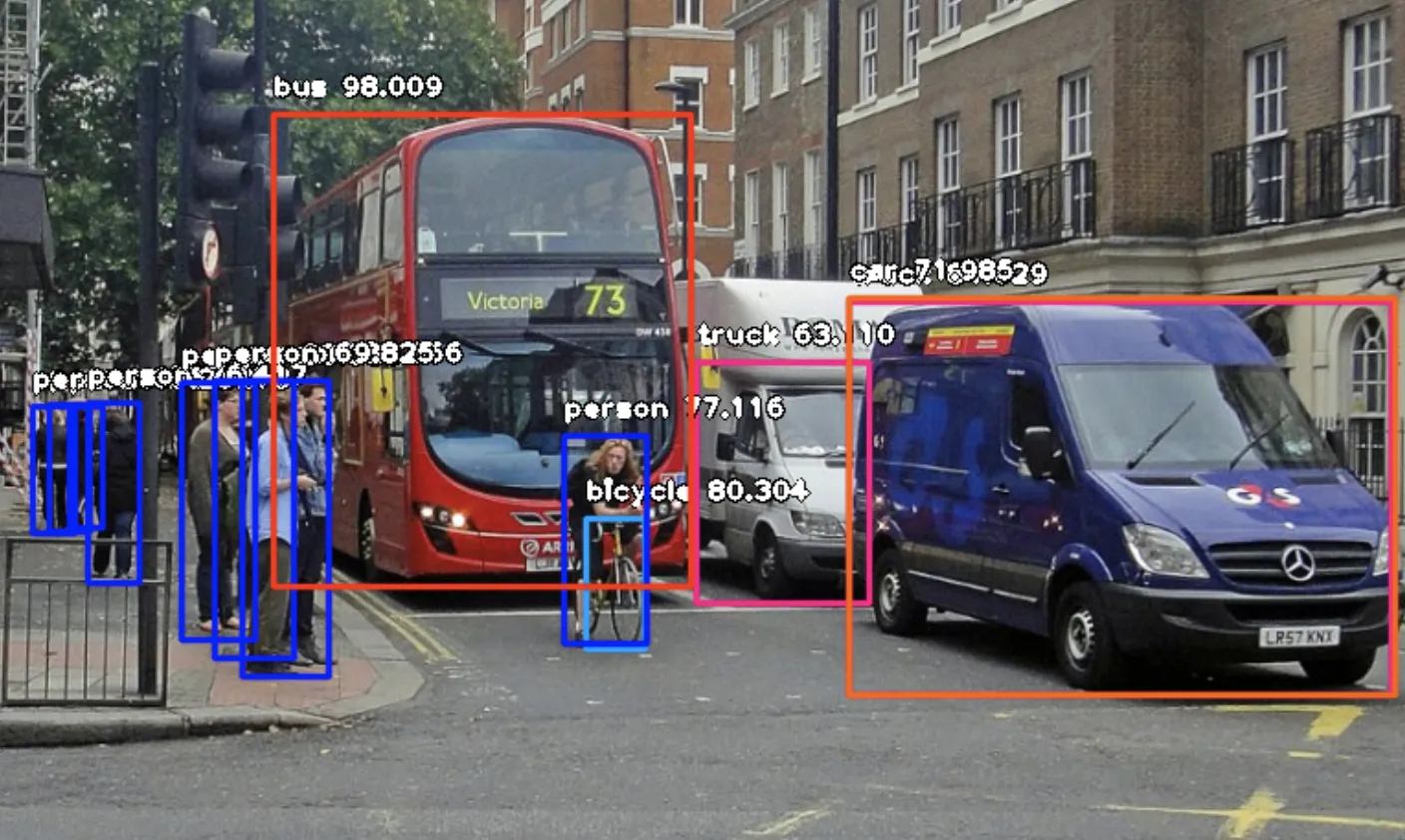
Source
OD lives only in the vision AI field, meaning that the only data asset used to solve an Object Detection task is visual data - images. You can argue that you can also apply Object Detection to videos, but in most cases, Data Scientists view videos as a series of frames and work with each frame separately. So, if you want to work on an OD project, you are most likely to work with distinct images.
Anyway, the general Object Detection algorithm is as follows:
- You take some prelabeled data as training input for your model. These annotations must include:
- Rectangular Bounding Box localizing an object;
- Target class label assigned to each Bounding Box.
- As a prediction output, you get a set of Bounding Boxes ((x, y) coordinates, width, and height of each rectangle) and a predicted class with a confidence score for each Bounding Box.
Speaking about how Object Detection compares with other vision AI tasks, there are several moments to highlight:
- In comparison to Semantic Segmentation, Object Detection models can identify distinct objects of target classes and count the number of them in an image;
- Bounding Box will inevitably contain more noise than a segmentation mask unless you have only rectangular objects to label. This will negatively affect the model’s performance, so if you think it is a problem and want to minimize the influence, please opt for the Instance Segmentation task;
- Object Detection is a less demanding task than Image Segmentation ones like Instance, Semantic, and Panoptic Segmentation, so OD should require less time, money, computational resources, and labeling effort.
What is Object Localization in Machine Learning?
In some academic papers, you might come across such a term as Object Localization. It is usually used in the same environment as Object Detection, so many people think they are synonyms and can be used interchangeably. This is wrong. Let’s put everything in its place.
The devil is in slight details, and the difference comes to the definition of these tasks. Object Detection and Object Localization are alike, but OD is unsure of the exact number of objects in an image.
In the Object Localization case, you will always have a picture with N objects. For example, N is two, and the target classes are Cat and Dog. In this case, images for an Object Localization task might look like follows:
An image with one cat and one dog;
An image with two dogs;
An image with two cats.
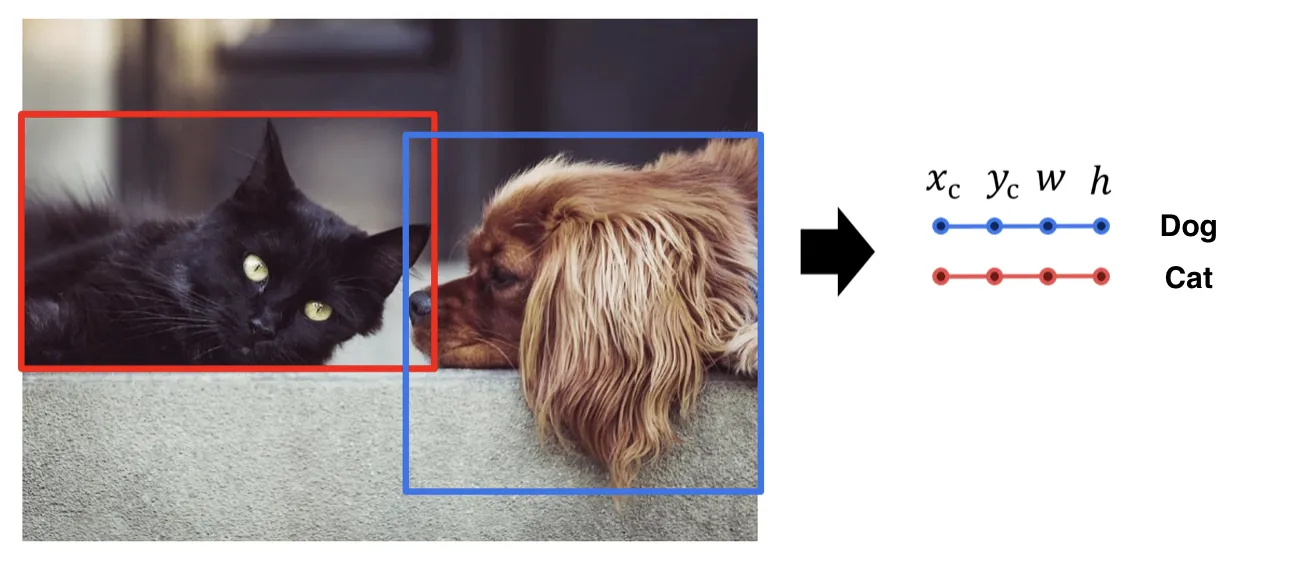
Source
Knowing the exact amount of outputs you need to predict makes a task and the approaches to solving it more straightforward. Unfortunately, in real life, in the majority of cases, you can not be sure of the number of objects in the picture. That is where Object Detection comes in. In the OD case, there is no N, and many objects of different target classes might be in the picture. Therefore, you do not know how many objects you would have to predict in advance.

Source
Object Detection real-life applications
From our experience, we cannot say that Object Detection is a prevalent Computer Vision task on the market, as Image Segmentation tasks simply give a more holistic output. Still, there is room for Object Detection to be proper in many tasks across various industries. Some of the most notable Object Detection real-life applications include:
- Face and people detection (in video surveillance and face recognition systems, supermarkets, public transport, and other crowded places);

Source
- Detection in retail (product detection in a smart refrigerator, autonomous systems of product monitoring on store shelves);

Source
Bank card recognition;
As a part of even more complicated systems and tasks (like autonomous driving systems, object tracking, activity recognition, etc);
And many other use cases.
Object Detection datasets
Speaking about datasets in the Computer Vision field, it is worth mentioning that the majority of them have annotations for various vision AI tasks within them (for example, a dataset might have labels for Instance Segmentation, Semantic Segmentation, and Object Detection all at once). It is neither good nor bad, but in general, it means that the creators had a lot to track when building a dataset which might have led to considerable annotation noise. From our experience, datasets specifically designed for a single Computer Vision task are more trustworthy regarding the quality of the annotations.
Still, it does not mean you should reject a dataset because it has labels for various tasks. Researchers use many benchmark datasets (both designed explicitly for the Object Detection cases and those that incorporate annotations for multiple tasks) in the Object Detection field to evaluate recent Object Detection model architectures and approaches. The most popular ones are:
- PASCAL VOC 2012 - contains 20 object categories, including vehicles, people, animals, etc;
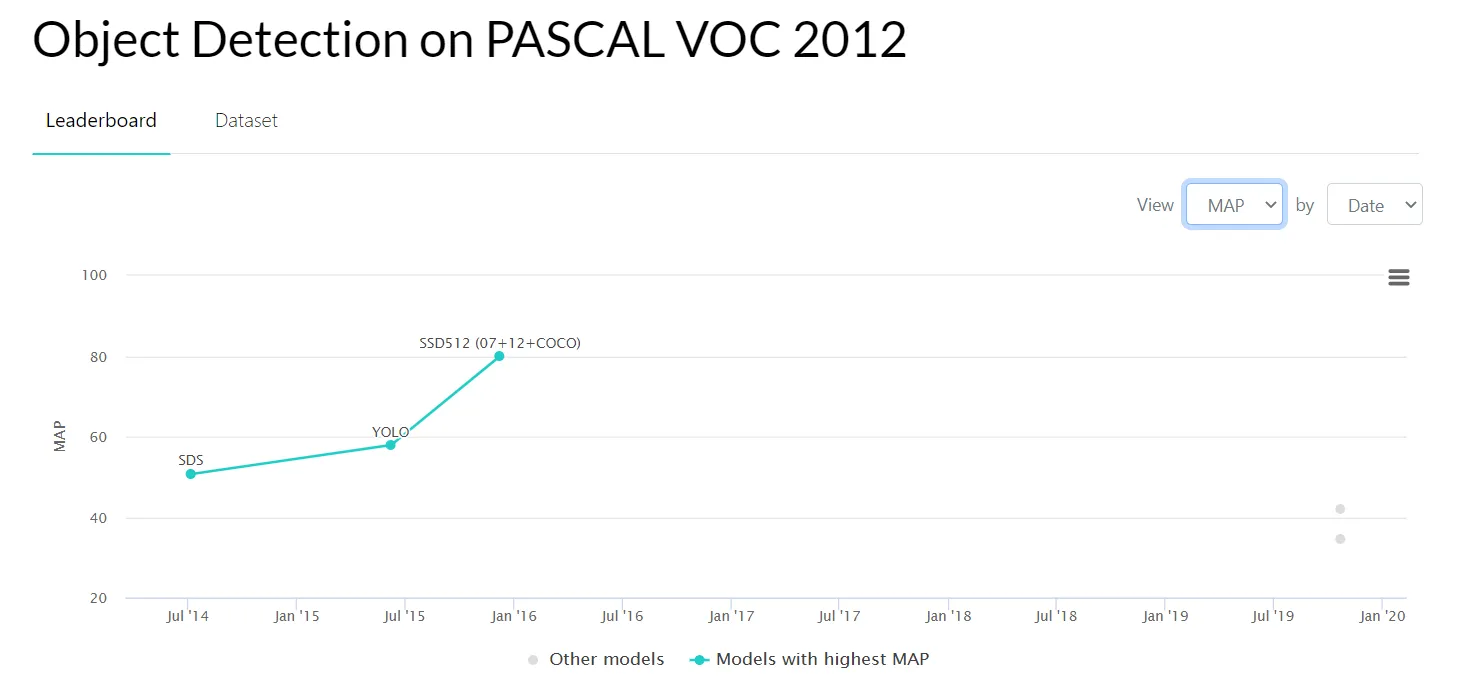
Source
- COCO (Common Objects in Context) - a large image dataset with everyday objects and humans;
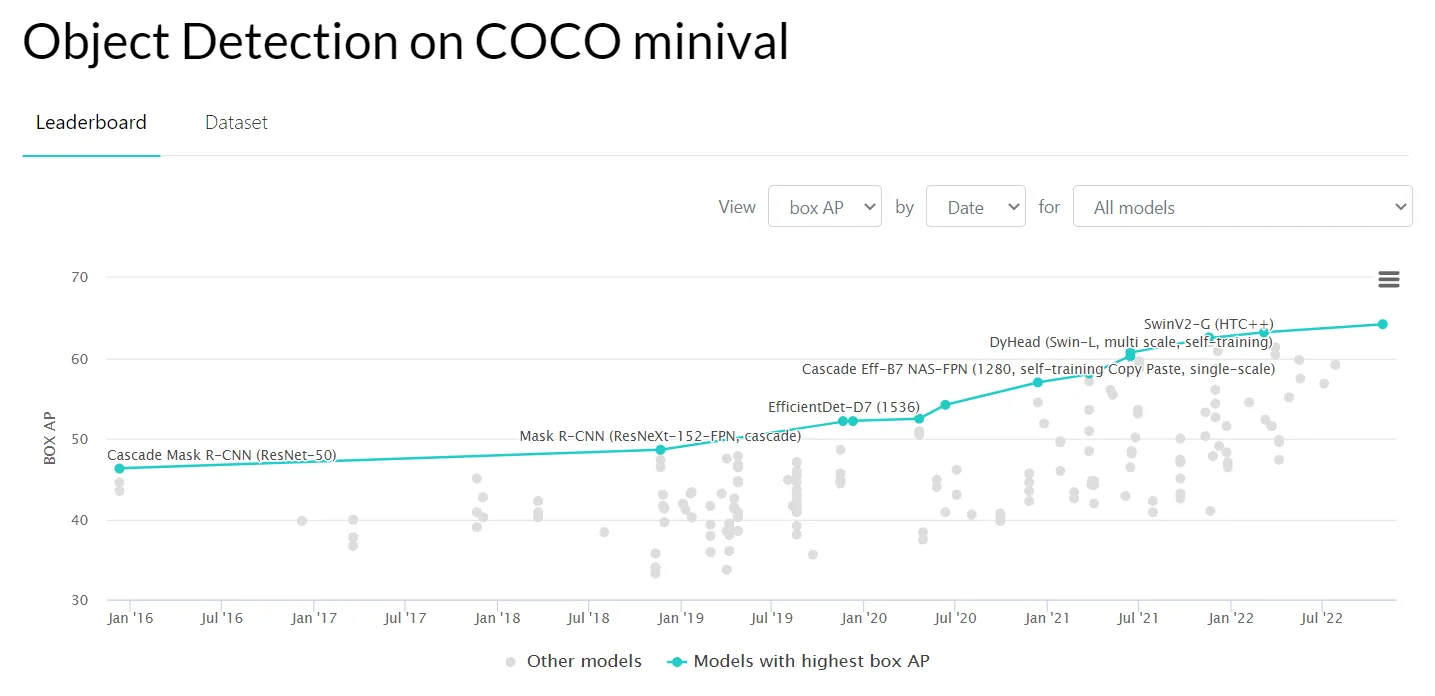
Source
- CrowdHuman - a benchmark dataset to better evaluate detectors in crowd scenarios;
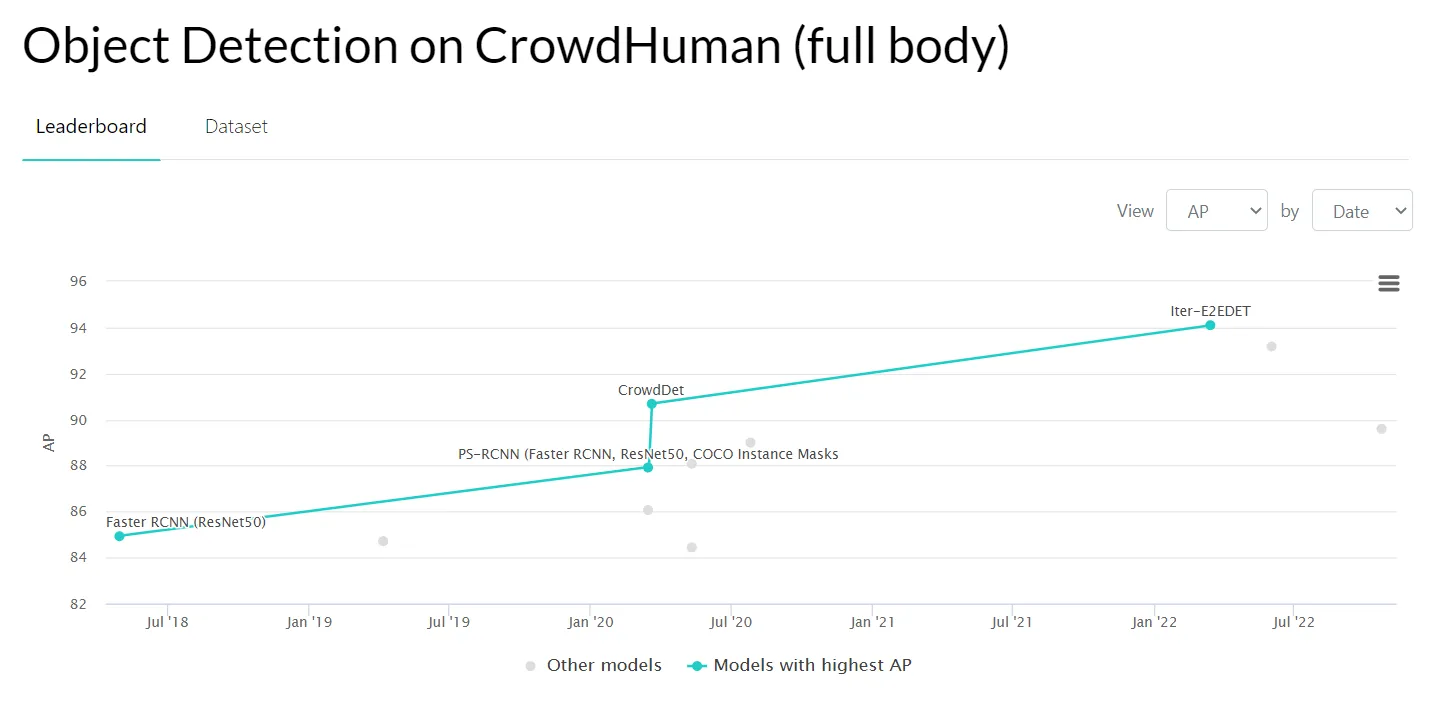
Source
- SeaDronesSee - a large-scale data set aimed at helping develop systems for Search and Rescue (SAR) using Unmanned Aerial Vehicles (UAVs) in maritime scenarios;
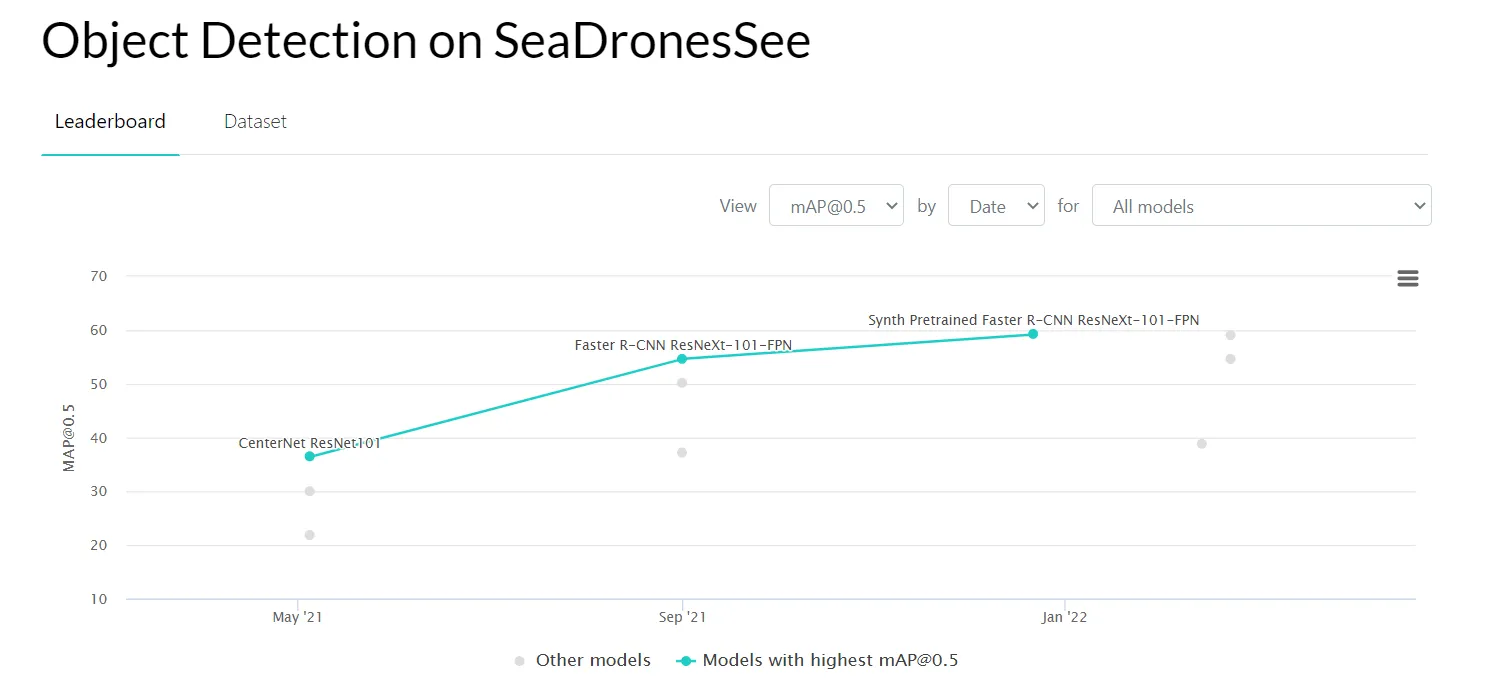
Source
- BDD100K - a large-scale driving video dataset;
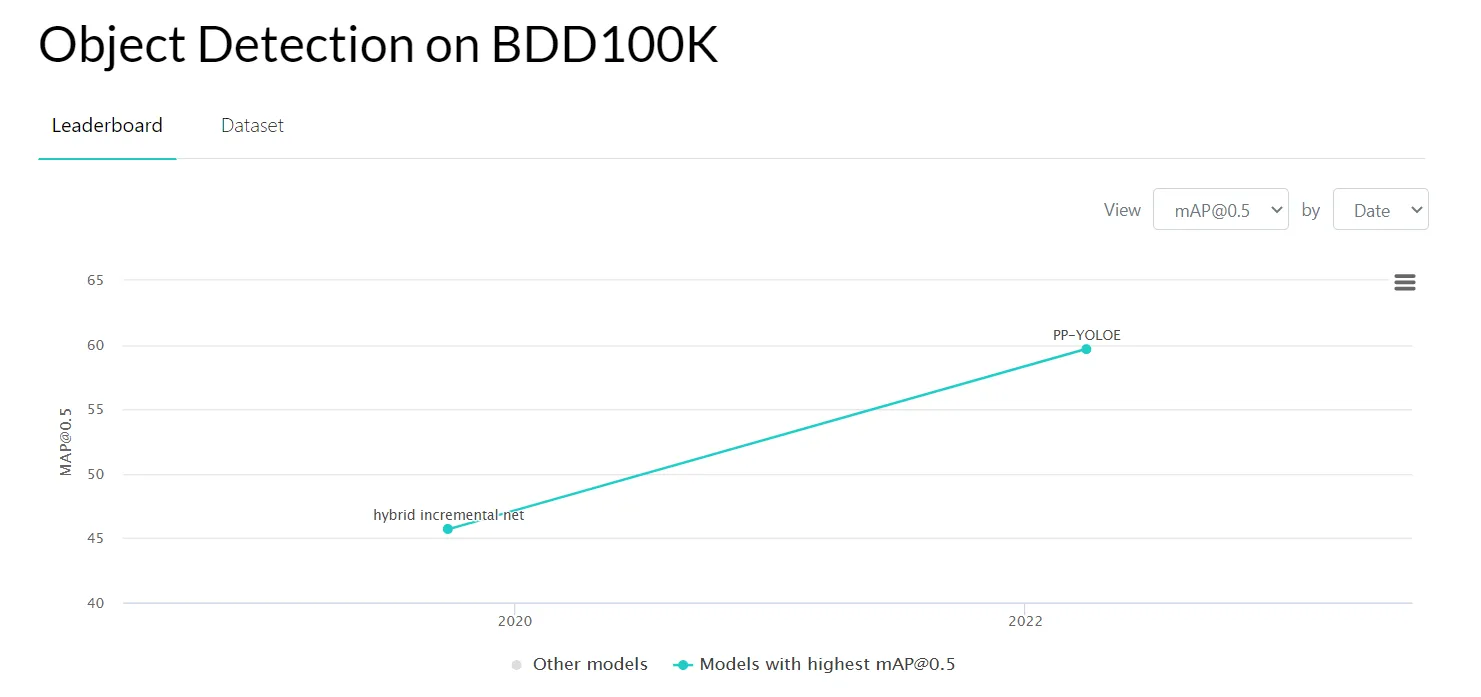
Source
- The Waymo Open Dataset - high-quality sensor data gathered by autonomous vehicles;
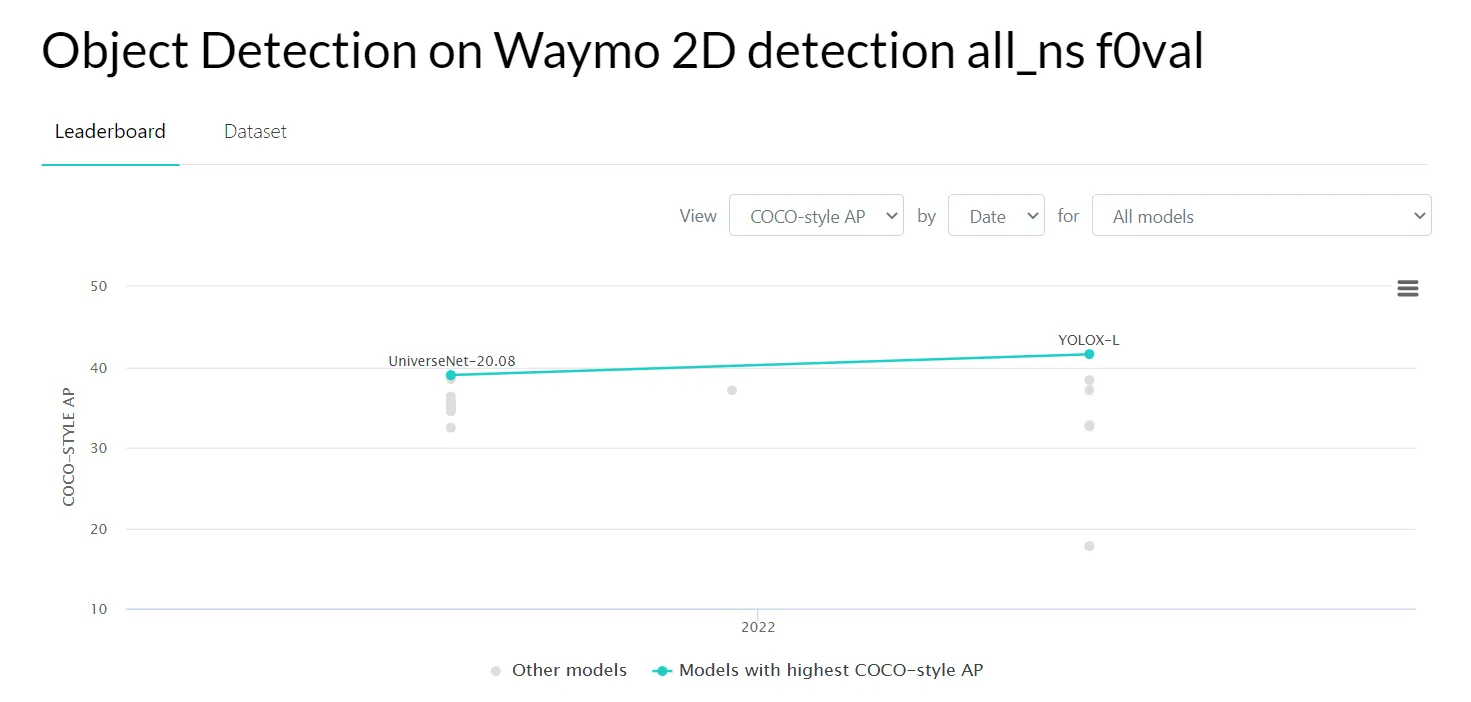
Source
- Open Images V6 - a dataset with 16 million bounding boxes for 600 object classes on 1.9 million images;
- LISA Traffic Sign Detection Dataset - as the name suggests, it contains annotated traffic light and signs data.
How do we solve an Object Detection task in CloudFactory?
Throughout years in the industry, CloudFactory's IT team has developed many internal instruments that our cloudworkers and Data Scientists use when working on client cases.
Let’s go through the available options step-by-step. To streamline the Object Detection annotation experience, CloudFactory's internal data labeling tool supports:
- The Bounding Box manual annotation tool;
- AI-powered Object Detection assistant that learns progressively and creates annotations for you.
As for the annotation quality control process, CloudFactory has you covered with its AI Consensus Scoring feature with a separate Object Detection review option. With the help of AI CS, you can find missing labels, extra labels, and different artefacts. Also, you will better understand how a machine sees your data, which might be valuable for your annotation strategy.
Regarding model development, CloudFactory's internal model-building tool supports many modern neural network architectures. For Object Detection, these include:
As a backbone for these architectures, CloudFactory offers:
- FBNetV2 C4;
- ResNet FPN;
- RetinaNet.
As a Machine Learning metric for the Object Detection case, CloudFactory implements mAP (mean Average Precision).
Hasty's YouTube channel features video tutorials of working on various Computer Vision tasks. Check out how it looks on the developer's side. Here is the one about Object Detection.
As of today, these are the key technical options CloudFactory has for Object Detection cases. If you want a more detailed overview, please check out the further resources or book some time with us to get deeper into CloudFactory with our help.