RMSprop
RMSprop is another optimization technique where there is a different learning rate for each parameter. The learning rate is varied by calculating the exponential moving average of the gradient squared and using it to further update the parameter.
Mathematically, the exponential moving average of the gradient squared is given as follows,
Here is one of the parameters and is the smoothing constant.
Then using to update the parameter
Here is the Base Learning Rate.
Notice some implications of such an update. If the change of w with respect to objective function was very high, then the update would decrease since we are dividing with a high value. Similarly, if the change of w with respect to the objective function was low then the update would be higher.
Let us clarify with a help of contour lines,
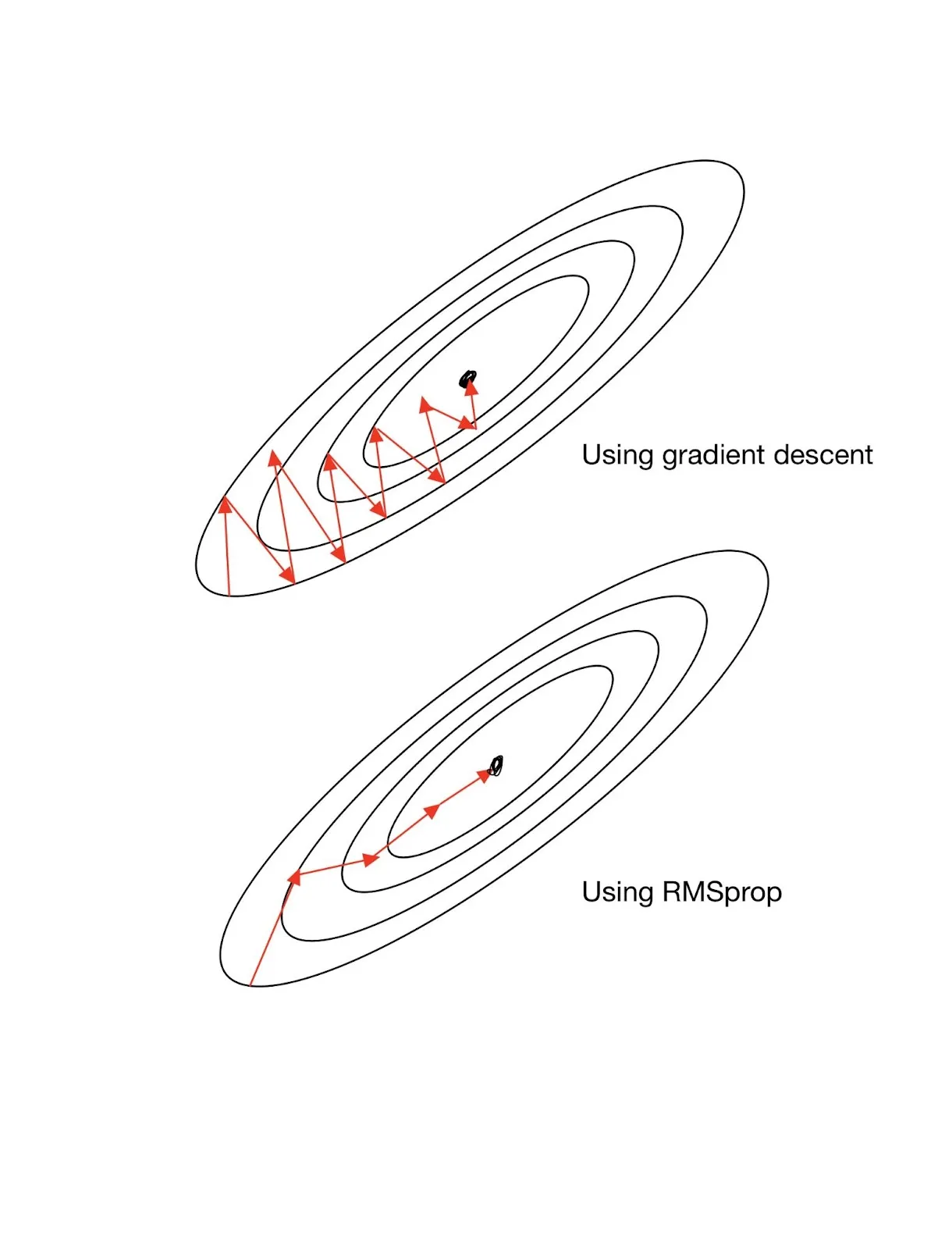
We can see that higher gradient in the vertical direction and the lower in the horizontal direction is slowing down the overall search process of the optimal solution. The use of RMSprop solves this problem by finding a better search “trajectory”.
Major Parameters
Alpha
Alpha is the same value at the in the aforementioned formula. Lower the value of alpha, lower the number of previous weights taken into account for the calculation of exponential moving average of squared gradients.
Centered
If "Centered" is activated, then the RMS prop is calculated by normalizing the gradients with the variance. If not, then the uncentered second moment, as in the aforementioned formula, is used.
Centering might help in the training process but will be slightly more computationally expensive.