Bounding Box Regression Loss
Object detection involves localization and classification. Localizing multiple objects in an image is mainly done by bounding boxes. The bounding box is predicted with a loss function that gives the error between the predicted and ground truth bounding box. Two types of bounding box regression loss are available in Model Playground: Smooth L1 loss and generalized intersection over the union.
Let us briefly go through both of the types and understand the usage.
Smooth L1 Loss
Smooth L1 loss, also known as Huber loss, is mathematically given as:
The squared term loss is used when the absolute loss falls below 1 and uses an absolute term otherwise. This makes it less sensitive to outliers and prevents exploding gradients. If the absolute loss is greater than 1, then the loss function is not squared which avoids high losses, and hence prevents exploding gradients.
Generalized Intersection over Union
Intersection over Union is the most popular evaluation metric used in object detection benchmarks. It has been shown that Intersection Over Union can be used as the objective function in object detection algorithms. Hence, our objective here would be to maximize the Intersection over Union. But there was a problem while using IoU as the loss function: if two non-overlapping objects were found, then the gradient of the loss would be zero and it couldn't be further optimized. Hence Generalized Intersection over Union was introduced which takes care of the non-overlapping objects by setting the metric to be a negative value.
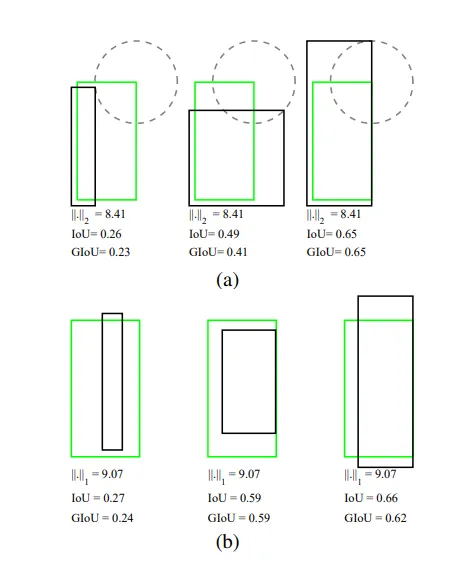
From the above picture, we can see that why using the simple L2 norm can be potentially misleading. For all the overlapping images in part a and part b, we can see that the L2 norm is the same even though the overlaps are different.