ReduceLROnPlateau
If you have ever worked on a Computer Vision project, you might know that using a learning rate scheduler might significantly increase your model training performance. On this page, we will:
- Сover the ReduceLROnPlateau (Reduce Learning Rate on Plateau) scheduler;
- Check out its parameters;
- See a potential effect from ReduceLROnPlateau on a learning curve;
- And check out how to work with ReduceLROnPlateau using Python and the PyTorch framework.
Let’s jump in.
ReduceLROnPlateau explained
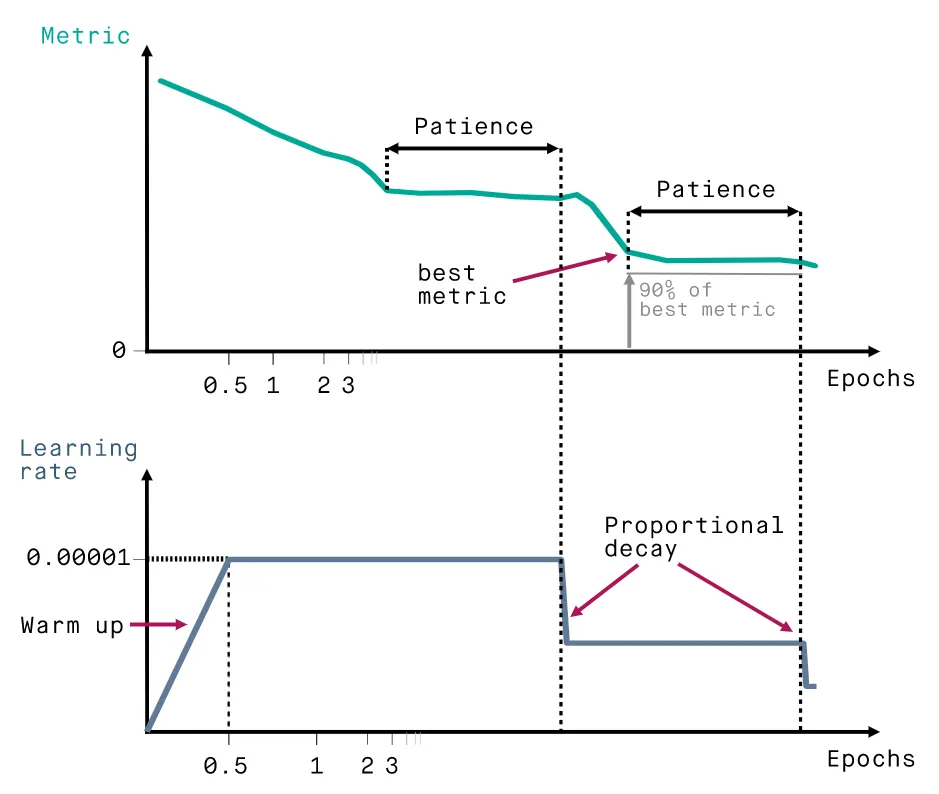
ReduceLROnPlateau is a scheduling technique that decreases the learning rate when the specified metric stops improving for longer than the patience number allows. Thus, the learning rate is kept the same as long as it improves the metric quantity, but the learning rate is reduced when the results run into stagnation.
The ReduceLROnPlateau scheduler is good to use when you are unsure how your model behaves with your data.
Parameters
- Mode:
- Min - the learning rate will be reduced when the monitored metric stops decreasing;
- Max - the learning rate will be reduced when the monitored metric stops increasing.
- Factor - a factor by which the learning rate will be reduced when the quantity stops improving. The formula is the following: new_learning_rate = learning_rate * factor.
- Patience - the number of epochs with no improvement, after which the learning rate is reduced. If the patience is 10, the algorithm ignores the first 10 epochs with no improvement in the quantity and reduces the learning rate in the 11th epoch.
- Threshold - the minimum value by which the quantity should change to count as an improvement. For example, if the threshold is 0.01 and the monitored quantity changes from 0.03 to 0.025, this is not counted as an improvement.
- Threshold mode - defines how exactly a dynamic threshold is calculated:
- Rel - dynamic threshold = best * (1+ threshold) in 'max' mode or best * (1- threshold) in 'min' mode;
- Abs - dynamic threshold = best + threshold in 'max' mode or best - threshold in 'min' mode.
- Cooldown - the number of epochs the algorithm would wait after the learning rate reduction before resuming normal operations (monitoring for improvements, calculating patience, and so on.)
- Min LR - the minimum learning rate for all the parameters. The learning rate would stay at this constant minimum once it reaches it.
- Eps - the minimum amount of decay applied to the learning rate. If the difference between the previous and current learning rates is less than Eps, then the update is ignored, and the previous learning rate is used.
ReduceLROnPlateau visualized
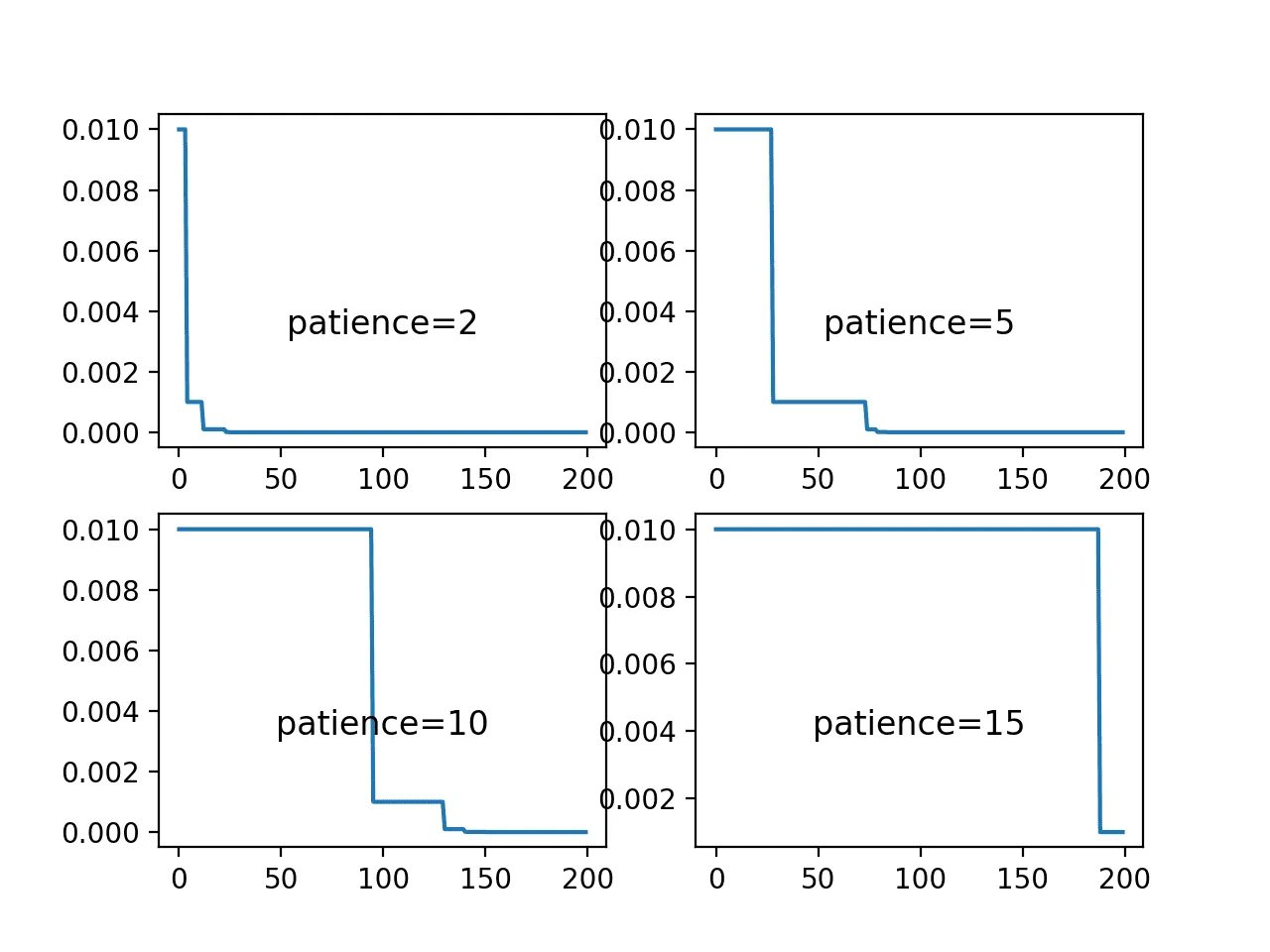
Source
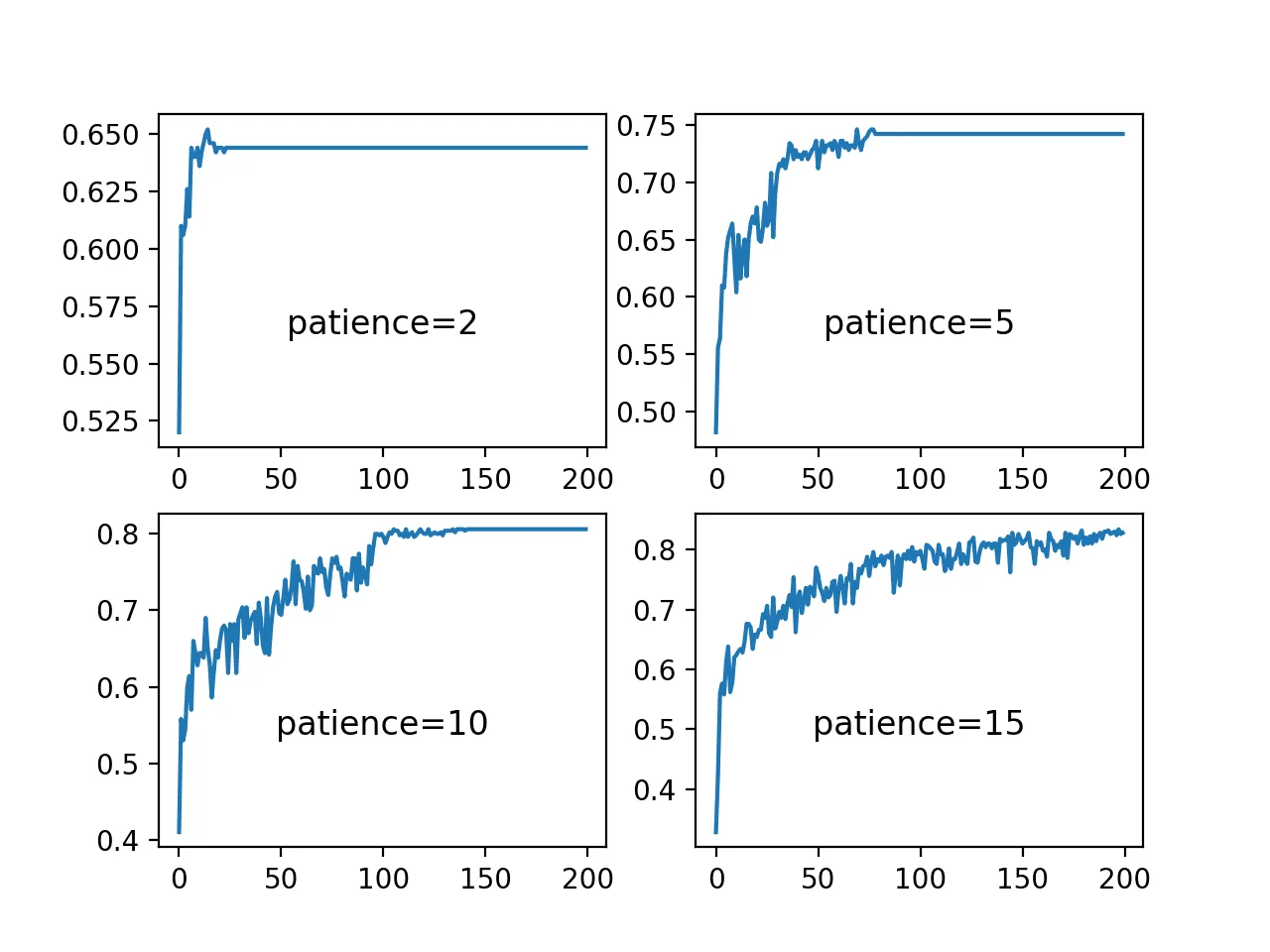
Source
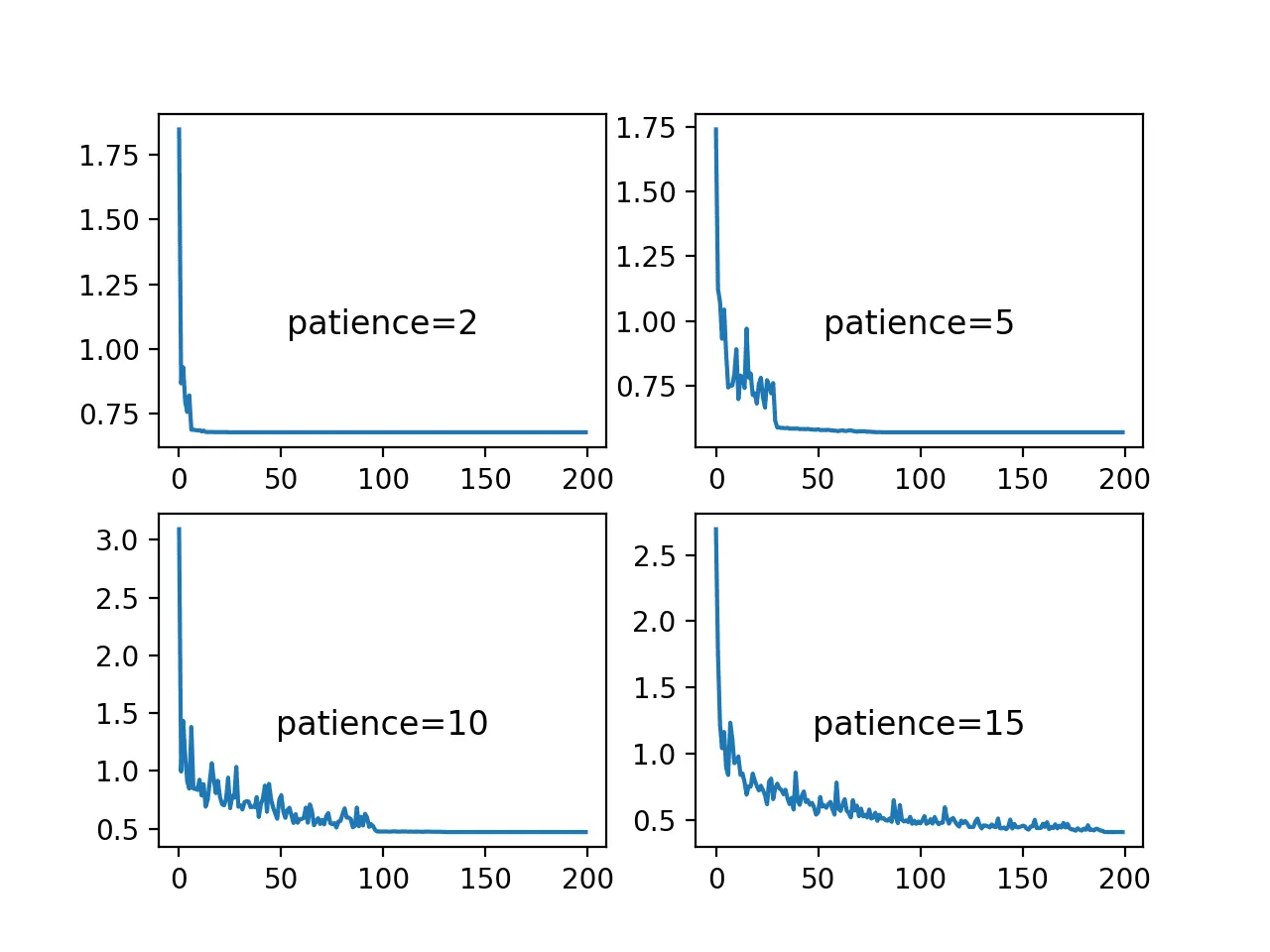
Source