F-score
If you have ever tried solving a Classification task using a Machine Learning (ML) algorithm, you might have heard of a well-known F-score ML metric. On this page, we will:
- Сover the logic behind the metric (both for the binary and multiclass cases);
- Check out the metric’s formula;
- Find out how to interpret the F-score value;
- Calculate F-score on simple examples;
- Dive a bit deeper into the Micro and Macro F-scores;
- And see how to work with the F-score using Python.
Let’s jump in.
What is F-score?
Precision and Recall are valuable metrics that are widely used across the industry. Still, they have a massive drawback. They produce two values that must be first analyzed separately and then together (check out the PR-curve page to learn more about the tradeoff between these metrics) to better understand an algorithm’s performance. So, to overcome this disadvantage, Data Scientists came up with a way to combine Precision and Recall into an aggregate quality metric.
To define the term, in Machine Learning, the F-score (or F beta score, or F-measure) is a Classification metric featuring a harmonic mean of Precision and Recall. To evaluate a Classification model using the F-score, you need to have the following:
The ground truth classes;
And the model’s predictions.
F-score formula
Unfortunately, F-measure is not an intuitive metric, especially when considering its formula. Moreover, the F beta score does not have any 'physical' meaning, for example, Accuracy is a fraction of the predictions that a model got right - the F-measure does not have such an explanation. It only makes the situation more challenging. So, we suggest you trust the Data Scientists using this metric daily that F-measure is helpful and trustworthy, and do not try to dive deeper unless you are really interested.
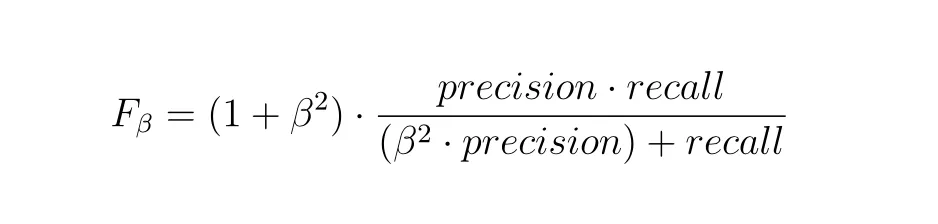
Source
As you can see, there is a beta parameter in the formula. To clarify, it determines the weight of Precision in the metric. In general, there are three most common values for the beta parameter:
F0.5 score (beta = 0.5): Such a beta makes a Precision value more important than a Recall one. In other words, it focuses on minimizing False Positives than minimizing False Negatives;
F1 score (beta = 1): True harmonic mean of Precision and Recall. In the best-case scenario, if Precision and Recall are equal to 1, the F-1 score will also be equal to 1;

Source
F2 score (beta = 2): Such a beta makes a Recall value more important than a Precision one. In other words, it focuses on minimizing False Negatives than minimizing False Positives.
Of these three cases, the most popular is the F1 score one, as it is the easiest to interpret. That is why the F1 score is the only F-score with its own sklearn function. Anyway, as you can see, F-measure can be easily described using Precision and Recall. The F beta score algorithm for the binary Classification task is as follows:
- Get predictions from your model;
- Pick your beta parameter value;
- Calculate the Precision and Recall scores;
- Use the formal F beta score formula (do not forget about the parameter value you picked);
- And analyze the obtained value.
Multiclass F-score
For the binary case, the workflow is straightforward. However, there are also multiclass use cases when things are a bit tricky. In general, there are various approaches you can take when calculating F-measure for the multiclass task. There are at least three different options, as you can see in the sklearn F beta score metric function:
Micro;
Macro;
And Weighted.
Each of these approaches is solid and can be very helpful in model evaluation. Also, in real life, you will likely calculate the metric value using all of them to get a more comprehensive view of a problem. Please check out the micro and macro F-measure calculation examples below or the scikit-learn documentation page if you want to learn more.
So, the F-score algorithm for the multiclass Classification task is as follows:
Get predictions from your model;
Pick your beta parameter value;
Identify the multiclass calculation approach you feel is the best for your task;
Use a Machine Learning library (for example, sklearn) to do the calculations for you;
And analyze the obtained value while considering the approach you used to get it and the parameter value you picked.
Interpreting F-score
In the F-score case, the metric value interpretation is straightforward. If you correctly classify more samples, higher Precision and Recall scores will give you a higher F-measure value. The higher the measured value, the better. For any beta parameter, the best possible value for F-measure is 1, and the worst is 0.
From our experience, for both multiclass and binary use cases, you should consider an F-score > 0.85 as an excellent score, an F-score > 0.7 as a good one, and any other score as the poor one. Still, you can set your own thresholds as your logic, beta parameter, and task might vary highly from ours.
Also, please always try to see the bigger picture when analyzing the obtained value. Having an excellent F-measure value is fantastic, but can you say the same about the Precision and Recall scores? Additionally, please remember that the beta parameter significantly impacts the metric. The ideal scenario is picking the beta parameter to match your task needs for the F-measure to produce good case-specific results. For example, use beta = 1 if Precision and Recall are equally significant to you, use beta = 0.5 if your emphasis is on Precision, or use beta = 2 if Recall is more critical for you.
F-score calculation example
Let’s say we have a binary Classification task. For example, you are trying to determine whether a cat or a dog is on an image. You have a model and want to evaluate its performance using the F1 score. You pass 15 pictures with a cat and 20 images with a dog to the model. From the given 15 cat images, the algorithm predicts 9 pictures as the dog ones, and from the 20 dog images - 6 pictures as the cat ones. First, let’s build a Confusion matrix (you can check the detailed calculation on the Confusion matrix page).
| Ground truth Cat | Ground truth Dog |
Predicted Cat | TP = 6 | FP = 6 |
Predicted Dog | FN = 9 | TN = 14 |
Excellent, now let’s calculate the F1 score using the formula for the binary Classification use case (the number of correct predictions is in the green cells of the table, and the number of the incorrect ones is in the red cells).
Precision = (TP) / (TP + FP) = (6) / (6 + 6) ~ 0.5
Recall = (TP) / (TP + FN) = (6) / (6 + 9) ~ 0.4
F1 score = 2 * (Precision * Recall) / (Precision + Recall) = 2 * (0.5 * 0.4) / (0.5 + 0.4) ~ 0.44
Ok, great. Let’s expand the task and add another class, for example, the bird one. You pass 15 pictures with a cat, 20 images with a dog, and 12 pictures with a bird to the model. The predictions are as follows:
15 cat images: 9 dog pictures, 3 bird ones, and 15 - 9 - 3 = 3 cat images;
20 dog images: 6 cat pictures, 4 bird ones, and 20 - 6 - 4 = 10 dog images;
12 bird images: 4 dog pictures, 2 cat ones, and 12 - 4 - 2 = 6 bird images.
Let’s build the matrix.
| Ground truth Dog | Ground truth Bird | Ground truth Cat |
Predicted Dog | 10 | 4 | 9 |
Predicted Bird | 4 | 6 | 3 |
Predicted Cat | 6 | 2 | 3 |
How to calculate F1 score for a multiclass case?
As mentioned above, in case you need to calculate the F-score for a multiclass scenario, you can try one of three approaches:
- Micro;
- Macro;
- And Weighted.
The same is true for the F1 score.
Macro F1 score calculation example
Macro F1 score is a way to study the classification as a whole. To calculate the Macro F1 score, you need to compute Macro Precision and Macro Recall and then use the F1 score formula. The Macro approach treats all the classes equally as it aims to see the bigger picture and evaluate the algorithm’s performance across all the classes in one value.
Let’s calculate the Precision value for each class. To do so, we need to go row by row (the green cell is the True Positives predictions for a specific class whereas red cells are False Positives):
Dog Precision: 10 / (4 + 9 + 10) ~ 0.43
Bird Precision: 6 / (4 + 3 + 6) ~ 0.46
Cat Precision: 3 / (6 + 2 + 3) ~ 0.27
Macro Precision score: (Dog Precision + Bird Precision + Cat Precision) / 3 = (0.43 + 0.46 + 0.27) / 3 ~ 0.386
Let’s calculate the Recall value for each class. To do so, we need to go column by column (the green cell is the True Positives predictions for a specific class whereas red cells are False Negatives):
Dog Recall: 10 / (4 + 6 + 10) ~ 0.5
Bird Recall: 6 / (4 + 2 + 6) ~ 0.5
Cat Recall: 3 / (9 + 3 + 3) ~ 0.2
Macro Recall score: (Dog Recall + Bird Recall + Cat Recall) / 3 = (0.5 + 0.5 + 0.2) / 3 ~ 0.4
In this case, the Macro F1 score will be:
Macro F1 score = 2 * (Macro Precision * Macro Recall) / (Macro Precision + Macro Recall) = 2 * (0.386 * 0.4) / (0.386 + 0.4) ~ 0.392
Micro F1 score calculation example
On the other hand, the Micro F1 score studies individual classes. To calculate it, you need to compute Micro Precision and Micro Recall and then use the F1 score formula. Thus, the Micro F1 score will combine the contributions of all classes to calculate the average metric.
Let’s calculate the Micro F1 score value for our use case
Micro Precision score: (TP Dog + TP Bird + TP Cat) / ((TP + FP) Dog + (TP + FP) Bird + (TP + FP) Cat) = (10 + 6 + 3) / ((4 + 9 + 10) + (4 + 3 + 6) + (6 + 2 + 3)) ~ 0.4
Micro Recall score: (TP Dog + TP Bird + TP Cat) / ((TP + FN) Dog + (TP + FN) Bird + (TP + FN) Cat) = (10 + 6 + 3) / ((4 + 6 + 10) + (4 + 2 + 6) + (9 + 3 + 3)) ~ 0.404
Micro F1 score = 2 * (Micro Precision * Micro Recall) / (Micro Precision + Micro Recall) = 2 * (0.4 * 0.404) / (0.4 + 0.404) ~ 0.401
F1-score in Python
The F-measure (F1 score primarily) is widely used in the industry, so all the Machine and Deep Learning libraries have their own implementation of this metric. For this page, we prepared three code blocks featuring calculating the F beta score in Python. In detail, you can check out:
- F-score in Scikit-learn (Sklearn);
- F-score in TensorFlow;
- F-score in PyTorch.
F1-score in Sklearn (Scikit-learn)
Scikit-learn is the most popular Python library for classical Machine Learning. From our experience, Sklearn is the tool you will likely use the most to calculate F-measure (especially, if you are working with the tabular data). Fortunately, you can do it in a blink of an eye.