Faster R-CNN
Faster R-CNN is an architecture for object detection achieving great results on most benchmark data sets. It builds directly on the work on the R-CNN and Fast R-CNN architectures but is more accurate as it uses a deep network for region proposal unlike the other two.
The breakthrough of Faster R-CNN is that it does the region proposals and classification predictions on the same feature map instead of using a sliding window approach and then splitting the tasks like its predecessors.
Intuition
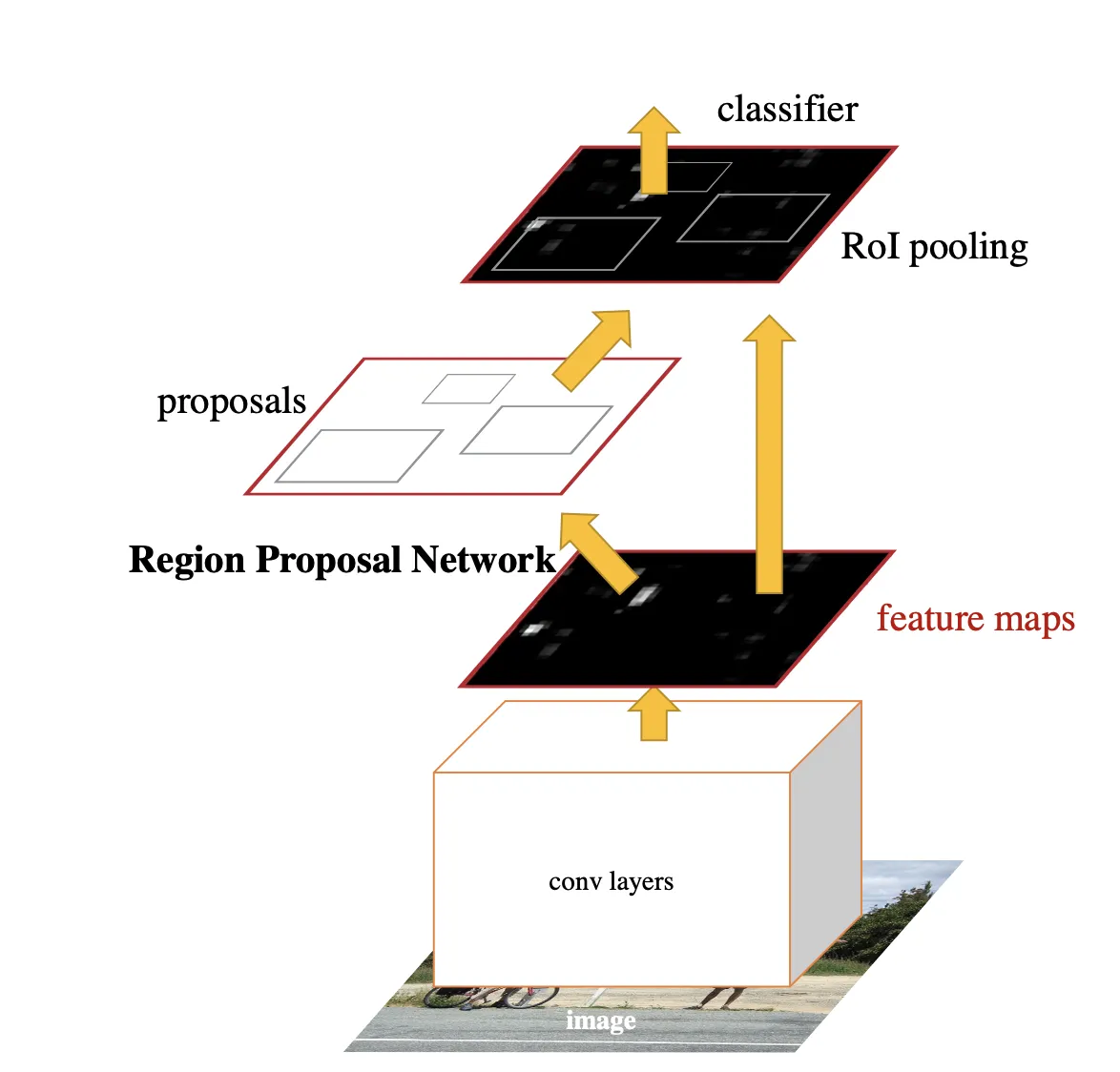
First, the architecture uses a backbone network to extract some features of the input image. Any classification architecture can be used, e.g., some ResNet variant combined with a Feature Pyramide Network (FPN).
Then, an anchor is generated for each feature, and for each anchor, a set of anchor boxes with variable sizes and aspect ratios are created.
RPN
The Region Proposal Network (RPN) detects the "good" anchor boxes, which will be forwarded to the next layer. The RPN consists of a classifier and a regressor.
The classifier predicts if an anchor box contains an object (IoU of anchor box with ground truth label is above a certain threshold) or contains parts of the background (IoU of anchor box with ground truth label is below a certain threshold).
Then, the regressor predicts offsets for the anchor boxes which contain objects to fit them as tightly as possible to the ground truth labels.
NMS
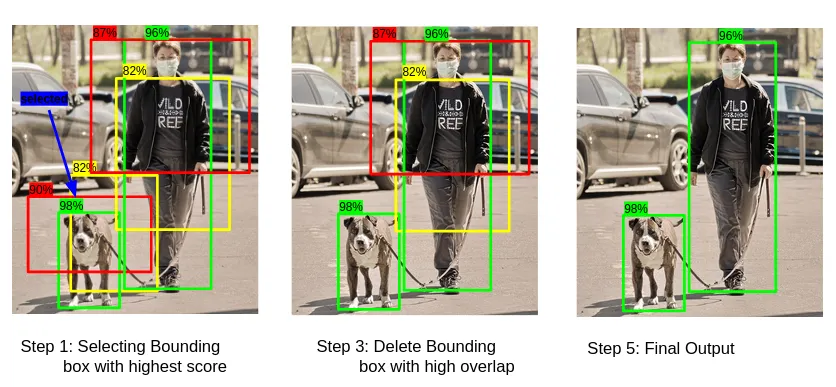
The RPN outputs a lot of noise, i.e., multiple bounding boxes for the same object. To reduce the noise and improve the performance of the overall model, Non-Max Suppression (NMS) is applied.
NMS works by identifying the bounding boxes with the highest confidence and then discarding the ones with high overlap:
Step 1: Select the box with the highest confidence (=objectiveness) score and pass it forward.\
Step 2: Then, compare the overlap (IoU) of this box with other boxes. \
Step 3: Remove the bounding boxes with high overlap (IoU > threshold, often 0.5). \
Step 4: Then, move to the box with the next highest confidence score. \
Step 5: Repeat steps 2-4 until all boxes have been checked.
ROI box head
Finally, the RoI pooling layer converts generated proposals of variable sizes to a fixed size to run a classifier and regress a bounding box on top of it.
Hyperparameters
Typically, the following hyperparameters are tweaked when using Faster R-CNN:
Backbone network
Specifying the architecture for the network on which Faster R-CNN is built.
IoU thresholds for RPN
These thresholds are used to decide if an anchor box generated contains an object or is part of the background.
Everything that is above the upper IoU threshold of the proposed anchor box and ground truth label will be classified as an object and forwarded. Everything below the lower threshold will be classified as background and the network will be penalized. For all the anchor boxes with an IoUbetween the thresholds, we're not sure if it's for- or background and we'll just ignore them.
Number of convolution filters in the ROI box head
How many convolution filters the final layer to make the classification contains. To a certain degree, increasing the number of filters will enable the network to learn more complex features, but the effect vanishes if you add too many filters and the network will perform worse (see the original ResNet paper to understand why you cannot endlessly chain convolution filters).
Number of fully connected layers in the ROI box head
How many fully connected layers (FC) the last part of the network contains. Increasing the number of FCs can increase performance for a computational cost, but you might overfit the sub-network if you add too many.
NMS number of proposals
Pre NMS
The maximum of proposals that are taken into consideration by NMS. The proposals are sorted descending after confidence and only the ones with the highest confidence are chosen.
Post NMS
The maximum of proposals that will be forwarded to the ROI box head. Again, the proposals are sorted descending after confidence and only the ones with the highest confidence are chosen.
Config for training
Low numbers of NMS proposals in training will result in a lower recall, but higher precision. Vice versa.
Config for testing
Here, the number of NMS proposals for the simple forward pass, e.g., inference, is defined. Less NMS proposals will increase inference speed, but higher numbers yield greater performance.
If you don't need super-fast inference, a good default is 1000 for post NMS number of proposals and 2000 for pre NMS.
Pooler Sampling Ratio
After extracting the Region of Interests from the feature map, they should be adjusted to a certain dimension before feeding them to the fully connected layer that will later do the actual object detection. For this, ROI Align is used which makes use of points that would be sampled from a defined grid, to resize the ROIs. The number of points that we use is defined by Pooler Sampling Ratio.
Pooler resolution
It is the size to pool proposals before feeding them to the mask predictor, in Model Playground default value is set as 7.
Depth of Resnet model
It is the depth variant of resnet to use as the backbone feature extractor, in Model Playground depth can be set as 18/50/101/152
Weights
It's the weights to use for model initialization, and in Model Playground R50-FPN COCO weights is used.
Code implementation
Further resources
- Entry for Object Detection
- Original paper
- Entry for Mask R-CNN, like Faster R-CNN but for Instance Segmentation
- NMS image source