DeepLabv3+
DeepLabv3+ is a semantic segmentation architecture that builds on DeepLabv3 by adding a simple yet effective decoder module to enhance segmentation results.
Multiple downsampling of a CNN will lead the feature map resolution to become smaller, resulting in lower prediction accuracy and loss of boundary information in semantic segmentation. Similarly, aggregating context around a feature helps in segmenting it better, which is accomplished with the atrous convolutions. DeepLabv3+ helps in solving these issues.
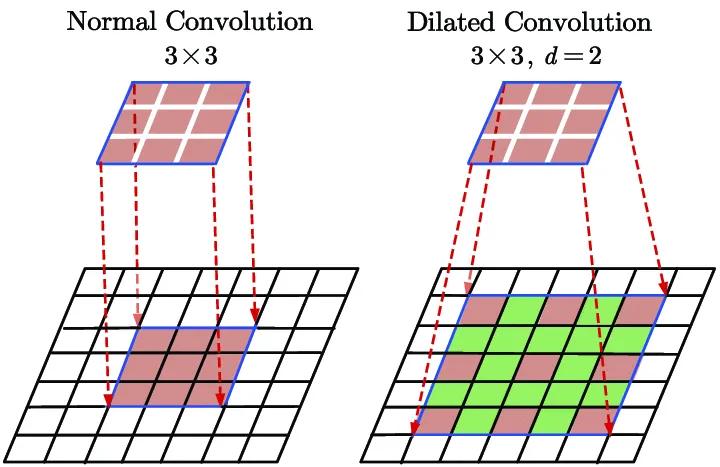
Atrous rate
Atrous Convolution/Dilated Convolution is a tool for refining the effective field of view of the convolution. It modifies the field of view using a parameter termed atrous rate. It is a simple yet powerful approach for enlarging the field of view of filters without affecting computation or the number of parameters.
DeepLabV3+ adds an encoder based on DeepLabV3 to fix the previously noted problem of DeepLabV3 consuming too much time to process high-resolution images.\
The application of the depthwise separable convolution to both atrous spatial pyramid pooling and decoder modules results in a faster and stronger encoder-decoder network for semantic segmentation.
Output stride
Output stride describes the ratio of the size of the input image to the size of the output feature map. It specifies how much signal reduction the input vector experiences as it passes the network.
In Model Playground, we have the option of having output stride as 8 or 16
In the architecture below, the encoder is based on an output stride of 16, i.e. the input image is down-sampled by a factor of 16.
Architecture
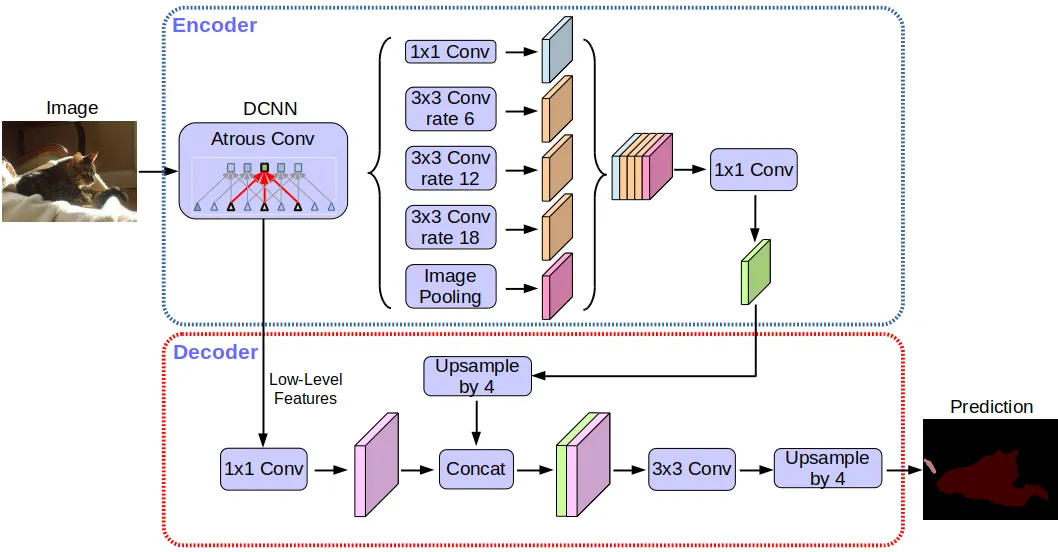
Encoder network
DeepLabV3+ employs Aligned Xception as its main feature extractor (encoder), although with substantial modifications. Depth-wise separable convolution replaces all max pooling procedures.
In Model Playground, we can select feature extraction (encoding) network to use as either Resnet or EffiecientNet.
Weights
It's the weights to use for model initialization, and in Model Playground ResNet101 COCO weights are used.
Code Implementation
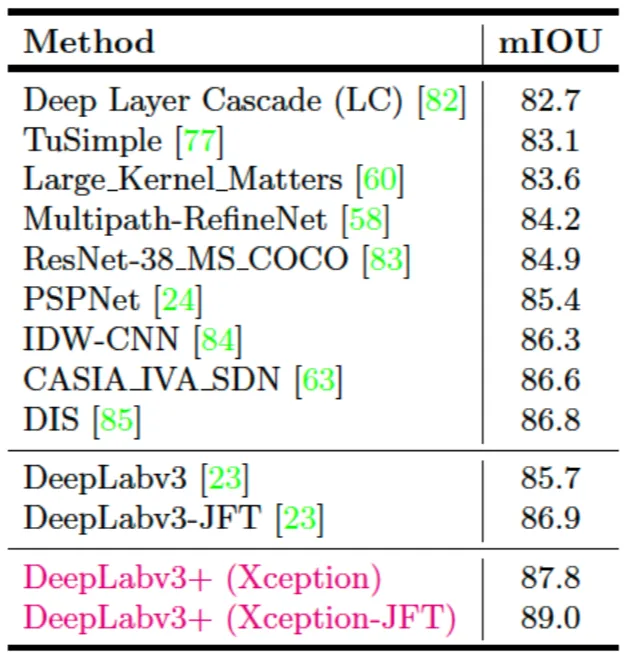
PASCAL VOC 2012 test set results with SOTA approaches