Momentum (SGD)
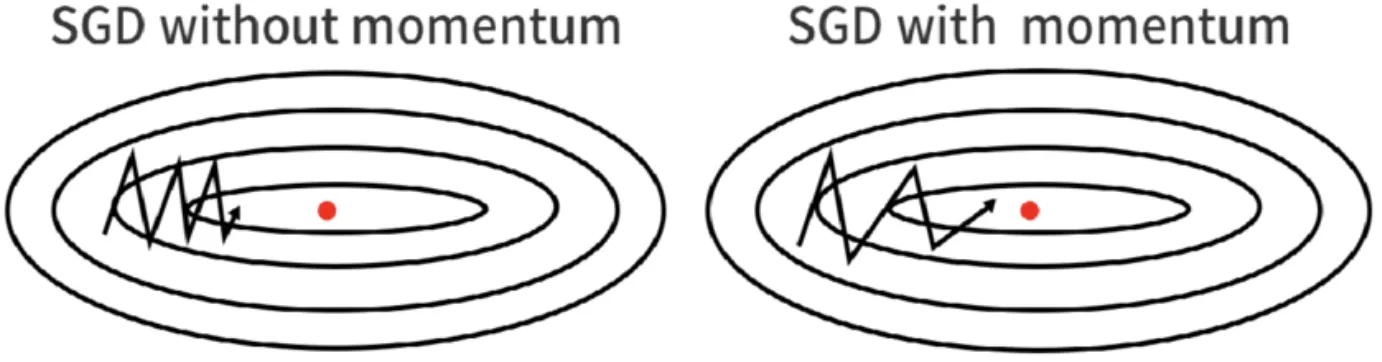
Momentum speeds up the SGD optimizer to reach the local minimum quicker. If we move in the same direction in the loss landscape, the optimizer will take bigger steps on the loss landscape.
A nice side effect of momentum is that it smooths the way SGD takes when the gradients of each iteration point into different directions.
Momentum is implemented by adding a term to the weight update rule of the SGD together with a parameter γ ranging between 0 and 1. But never ever set it to 1, then bad things will happen!
Without dampening, momentum might cause you to miss the minimum because momentum increased the step size so much that the optimizer 'jumps over' it.