LinkNet
The majority of the segmentation architectures like Pyramid Architecture Network, PSPnet, and U-Net have used the encoding-decoding strategy. The encoder encodes information into feature space, and the decoder maps this information into spatial categorization to perform segmentation. Since the encoder encodes the information in feature space, the image is heavily downsampled. The major issue with semantic segmentation is upsampling this feature map to the original resolution and preserving the categorization of the pixels.
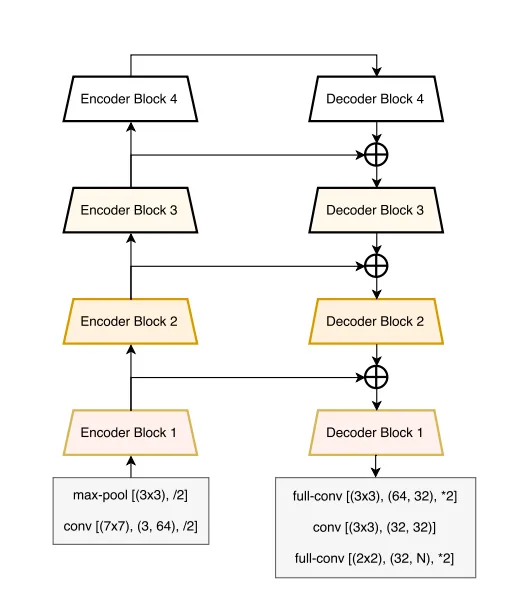
In LinkNet, the input of each encoder layer is also passed to the output of its corresponding decoder. By doing this lost spatial information is recovered that can be used by the decoder and its upsampling operations.
Source
We can see the passing of the encoded information to the corresponding decoder block.
Parameters
Encoder Network
The network that extracts the feature map. Here, the encoder network can be selected to be ResNet or Efficient Net.
Weights
It is the initialization of the weights of the LinkNet. Here, the weights are initialized randomly.