HybridTask Cascade
HybridTask Cascade (HTC) is a neural network architecture that develops the ideas of Mask R-CNN and Cascade Mask R-CNN, making Instance Segmentation models even more advanced. In Hasty, HTC is one of the available NN architecture options for an Instance Segmentation task.
Beyond HTC, Hasty also implements the following options:
On this page, we will dig deeper into the HybridTask Cascade architecture to see how it differs from other variants. Let’s jump in.
HybridTask Cascade architecture explained
As the name suggests, HybridTask Cascade architecture is a part of the Cascade family. As you might know, the original Cascade concept was quite successful in various vision AI tasks, such as Object Detection.
However, researchers struggled to design a successful Instance Segmentation architecture until HTC was proposed. HybridTask Cascade was intentionally built to be an Instance Segmentation Cascade with a strong relationship between the Detection and Segmentation parts.
Source
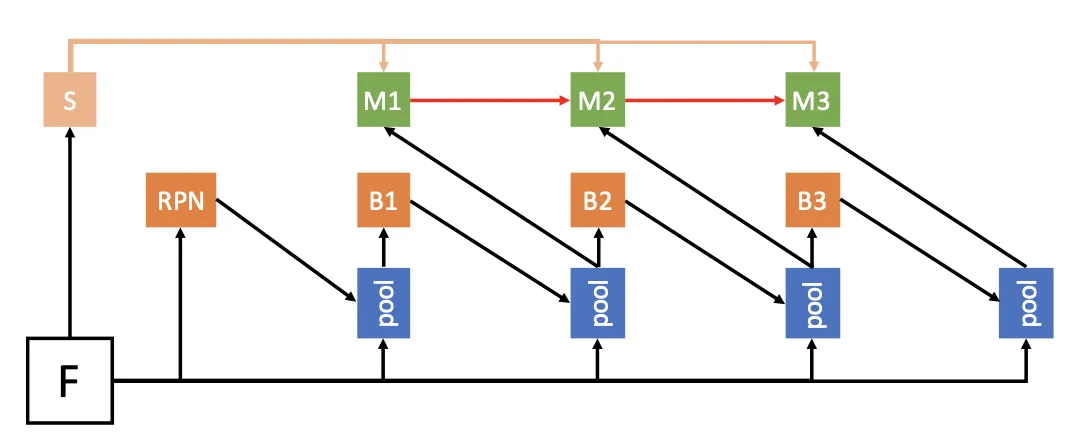
So, in the original HTC paper, researchers highlight the following distinctions of HybridTask Cascade compared to the existing architectures:
HTC interleaves bounding box regression and mask prediction processes instead of executing them in parallel;
HTC incorporates a direct path to reinforce the information flow between mask branches by feeding the mask features of the preceding stage to the current one;
HTC aims to explore more contextual information by adding a Semantic Segmentation branch and fusing it with box and mask branches.
These changes helped to effectively improve the information flow, not only across Cascade stages but also between tasks (Semantic Segmentation, mask, and box branches), resulting in a considerable metric boost compared to other solutions.
Model Playground: Parameters
Weights
The weights that are used to initialize the neural network. In the HybridTask Cascade case, Hasty uses the R50 HybridTask Cascade weights gained on COCO.
The depth of the backbone ResNet model
This parameter defines the depth variant of the backbone ResNet model used as a feature extractor. In Model Playground, we have 50 and 101 options implemented.
Stages to Freeze
Freezing the stages in a neural network is a technique introduced to reduce computation expenses. If you freeze some first stages, the architecture will not have to backpropagate through them. Freezing many stages will help the computation be faster, but aggressive freezing might degrade the model output and can result in sub-optimal predictions.