Image Classification
Computer Vision (CV) is a scientific field that researches software systems trained to extract information from visual data, analyze it, and draw conclusions based on the analysis. The area consists of so-called CV or vision AI tasks. Each task is unique and incorporates techniques and heuristics for acquiring, processing, analyzing, understanding the data, and extracting various details from it. The most basic and well-known task is Classification. On this page, we will:
- Understand the basics of the Image Classification field in Machine Learning;
- Cover in-depth the Image Classification vision AI task;
- Compare Binary, Multi-class, and Multi-label Classification;
- Research the real-life applications of Image Classification;
- Cover some popular Image Classification datasets and SOTA results on them;
- See features that CloudFactory uses for streamlining an Image Classification task.
Let’s jump in.
What is Image Classification in Machine Learning?
In everyday life, Classification refers to assigning a class label to a specific object. In a sense, it is the most common task every person does daily. For example, when you see a dog on the walk, you classify it as belonging to a specific breed. And this is how it works with any object you can see around you. So, Classification is one of the basic tasks our brain solves.
Fortunately, when it comes to Machine and Deep Learning (ML and DL), the Classification definition is not that different from the one we have just discussed. In the Artificial Intelligence field, Classification is a Supervised Learning task that focuses on assigning a class (label) to a given data asset.
In ML and DL, you can classify many objects, the most popular being:
Images;
Videos;
Texts;
Documents;
Tabular data;
etc.
Anyway, the general Classification algorithm in all ML is as follows:
You take some prelabeled data as training input for your model;
You get the probability vector as a prediction output;
You analyze the obtained vector based on standard heuristics or your own logic and formulate the final prediction.

Source
Still, drawing a clear-cut difference between Classification in Machine and Deep Learning is essential. Fortunately, there is no difference in how we interpret Classification in these fields except for the data used for analysis and the methods used to address the challenge. In conventional Machine Learning, Classification is usually performed upon tabular data using standard ML algorithms such as Logistic Regression, Decision Tree, Random Forest, etc. On the other hand, in Deep Learning, researchers use neural networks to analyze more difficult data assets, for example, images.
Additionally, in Computer Vision, Image Classification might be a part of more challenging tasks such as Instance Segmentation, Semantic Segmentation, Object Detection, etc. However, sometimes researchers solve Classification as a standalone task.
Image Classification Vs. Image Tagging
In some academic papers, you might come across such a term as Tagging. It is usually used in the same environment as Classification, so many people think they are synonyms and can be used interchangeably. This is wrong. Let’s put everything in its place.
The Classification task can be divided into two major parts:
Single-label Classification - you assign a single class to your object (for example, an image);
Binary Classification;
Multi-class Classification;
Multi-label Classification - you assign multiple classes to your object.
Multi-label Classification is often referred to as Image Tagging. This is where the confusion comes from. So, in a very particular case, when you speak about Multi-label Classification, you can use the Classification and Tagging terms interchangeably.
Let’s take a closer look at each variation of the Classification task.
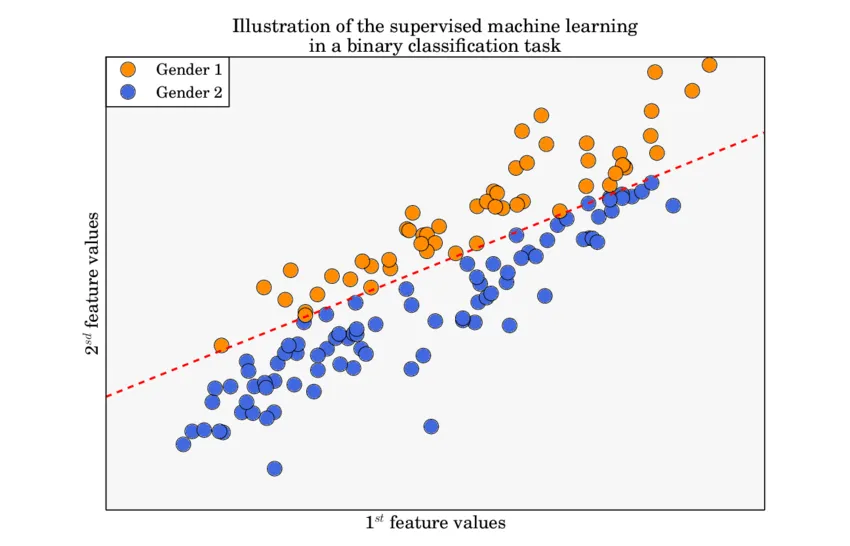
What is Binary Classification?
Binary Classification is such a Classification that operates with two classes only. Usually, these class labels are mapped to the values 0 and 1. For instance, the class True corresponds to 1 and False to 0. So the ultimate goal is to predict one of two classes.
The general Binary Classification algorithm in all ML is as follows:
You take some prelabeled data as input for your model;
You get the probability vector as an output (for example, [0.3, 0.7]);
You analyze the obtained vector based on standard heuristics or your own logic and formulate the final prediction. In our case, the highest probability (0.7) is in the second slot, which means that the model thinks an object corresponds to class 2 with a high chance.
Source
In a real-life scenario, we regularly come across Binary Classification problems. Some good examples of these might be:
Is the patient healthy or sick?
Is the received email spam or not?
Is the answer to the question yes or no?
Should I choose this option or another one?
As for the algorithms you can use to solve a Binary Classification task, it depends on whether you aim to solve a Machine or Deep Learning Classification problem:
Machine Learning Binary Classification algorithms;
Logistic Regression;
Support Vector Machine (SVM);
k-Nearest Neighbors;
Decision Tree;
Random Forest;
etc.
Deep Learning Binary Classification algorithms - basically, any convolutional neural network architecture;
ResNet;
MobileNet (all versions);
EfficientNet;
SWIN;
ConvNeXt;
ResNeXt;
etc.
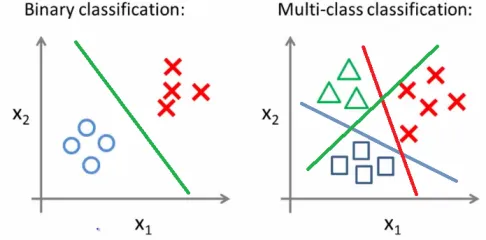
What is Multi-class Classification?
Multi-class Classification is such a Classification that operates with more than two classes. The number of labels can vary from 3 to large quantities. For instance, one can build a model that classifies letters of the alphabet or one of the thousands of items at a groceries store.
The general Multi-class Classification algorithm in all ML is as follows:
You take some prelabeled data as input for your model;
You get the probability vector as an output (for example, [0.1, 0.2, 0.7]);
You analyze the obtained vector based on standard heuristics or your own logic and formulate the final prediction. In our case, the highest probability (0.7) is in the third slot, which means that the model thinks an object corresponds to class 3 with a high chance.
Source
Like in the Binary case, we regularly encounter Multi-class Classification problems in real-life scenarios. Some good examples of these might be:
Classifying animals by their species;
Classifying clients by their behavior;
Sentiment analysis of a sentence (sad, happy, neutral, etc.).
As for the algorithms you can use to solve a Multi-class Classification task, it depends on whether you aim to solve a Machine or Deep Learning Classification problem:
- Machine Learning Multi-class Classification algorithms;
- Logistic Regression;
- Support Vector Machine (SVM);
- k-Nearest Neighbors;
- Decision Tree;
- Random Forest;
- etc.
- Deep Learning Multi-class Classification algorithms - basically, any convolutional neural network architecture;
- ResNet;
- MobileNet (all versions);
- EfficientNet;
- SWIN;
- ConvNeXt;
- ResNeXt;
- etc.
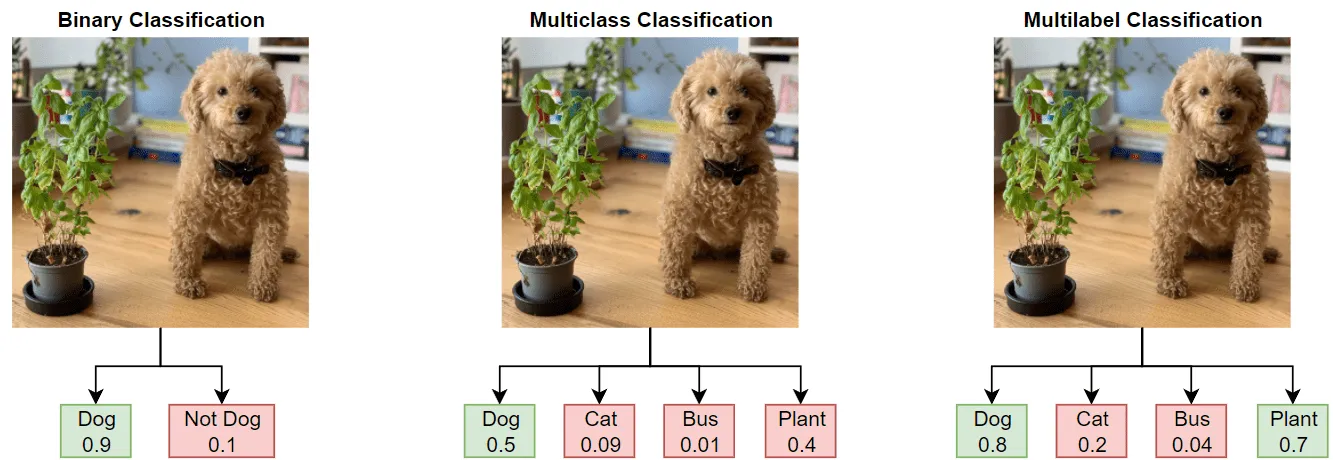
What is Multi-label Classification?
Multi-label Classification is such a Classification that can operate with more than two classes and allows you to assign more than one label to an image.
The general Multi-label Classification algorithm in all ML is as follows:
You take some prelabeled data as input for your model;
You get the probability vector as an output (for example, [0.1, 0.35, 0.7]);
You analyze the obtained vector based on standard heuristics or your own logic and formulate the final prediction. For example, you can set a certain threshold which you can use to decide whether to assign a class to an image or not based on predicted probability. Let’s say that, in our case, the threshold is 0.3. As you can see, two values are above the threshold so that we can assign classes 2 and 3 to an image based on our logic.
Source
Widespread examples of Multi-label Classification are when an object can simultaneously be assigned to many classes. A good example might be classifying movies by their genre.
As for the algorithms you can use to solve a Multi-label Classification task, it depends on whether you aim to solve a Machine or Deep Learning Classification problem:
- Machine Learning Multi-label Classification algorithms - many standard ML algorithms support Multi-label cases;
- k-Nearest Neighbors;
- Decision Tree;
- Random Forest;
- Ridge;
- etc.
- Deep Learning Multi-label Classification algorithms - basically, any convolutional neural network architecture with some logic built upon its output;
- ResNet;
- MobileNet (all versions);
- EfficientNet;
- SWIN;
- ConvNeXt;
- ResNeXt;
- etc.
Binary Classification Vs. Multi-class Classification Vs. Multi-label Classification
Binary Classification | To predict whether the input falls or does not fall into a certain category. Operates with two classes only. | Table data/text data/image/etc. Examples:
| Probability vector. The goal is to pick one of two labels Examples:
|
Multi-class Classification | To predict the most probable class of the input out of many. | Table data/text data/image/etc. Examples:
| Probability vector. The goal is to pick one class out of multiple labels. Examples:
|
Multi-label Classification | To predict all the classes the input might be assigned to. Can operates with many classes (more than two) | Table data/text data/image/etc. Example:
| Probability vector. The goal is to pick one or several classes out of multiple labels. Example:
|
Image Classification real-life applications
Classification is one of the most basic tasks in all Machine and Deep Learning which is widely used both as a standalone challenge and as a part of more challenging tasks. Some popular applications of a self-contained Classification task include:
- Agricultural challenges (for example, classifying crops as damaged or healthy);
- Handwritten digit recognition (from 0 to 9);

Source
- Categorizing emotions on a human’s face;
- Identifying whether the person is a child or an adult;
- Classifying the patient’s state of health by an image (medical image processing);
- And many more use cases.
Image Classification datasets
You can find many free datasets that can be used to solve all sorts of Deep Learning Classification tasks on the Web. The most popular ones are:
- ImageNet - a large visual database with more than 14 million images;
Source
- CIFAR-10 - a dataset comprising 60000 32x32 color images in 10 classes, with 6000 images per class;
Source
- CIFAR-100;
- MNIST (Modified National Institute of Standards and Technology) database - an extensive collection of handwritten digits;
Source
- Street View House Numbers (SVHN) - a large digit classification benchmark dataset.
Source
How do we solve an Image Classification task in CloudFactory?
Throughout years in the industry, CloudFactory's IT team has developed many internal instruments that our cloudworkers and Data Scientists use when working on client cases.
Let’s go through the available options step-by-step. To streamline the Image Classification annotation experience, CloudFactory's internal data labeling tool supports:
As for the annotation quality control process, CloudFactory has you covered with its internal AI Consensus Scoring feature with a separate Class review option. With the help of AI CS, expert annotators find misclassified labels and fix them in a couple of clicks. Also, such a tool gives a better understanding of how a machine sees the data, which might be valuable for the annotation strategy.
Regarding model development, CloudFactory's internal model-building tool supports many modern neural network architectures. For Image Classification, these include:
- ResNet;
- RetinaNet;
- MobileNetV2;
- SWIN;
- ConvNeXt.
As a Machine Learning metric for the Image Classification case, CloudFactory uses:
- Accuracy for Classifer;
- F-beta score for Classifier;
- HammingScore for Tagger;
- Precision and Recall (for both).
As of today, these are the key technical options CloudFactory uses for the Image Classification cases. If you want a more detailed overview, please check out the further resources or book some time with us to get deeper into CloudFactory with our help.