Cross-Entropy Loss
Cross-entropy loss is a widely used alternative for the squared error. It is used when node activations can be understood as representing the probability that each hypothesis might be true, i.e., when the output is a probability distribution. Thus, it is used as a loss function in neural networks with softmax activations in the output layer.
Calculation / Interpretation
Cross entropy indicates the distance between what the model believes the output distribution should be, and what the original distribution really is.
Where is the true label and is the probability of the label.
The goal for cross-entropy loss is to compare how well the probability distribution output by Softmax matches the one-hot-encoded ground-truth label of the data.
It uses the log to penalize wrong predictions with high confidence stronger.
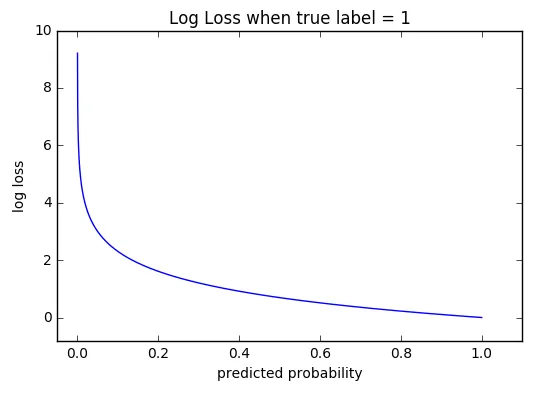
The cross-entropy loss function comes right after the Softmax layer, and it takes in the input from the Softmax function output and the true label.
Interpretation of Cross-Entropy values:
- Cross-Entropy = 0.00: Perfect predictions.
- Cross-Entropy < 0.02: Great predictions.
- Cross-Entropy < 0.05: On the right track.
- Cross-Entropy < 0.20: Fine.
- Cross-Entropy > 0.30: Not great.
- Cross-Entropy > 1.00: Terrible.
- Cross-Entropy > 2.00 Something is seriously broken.