Semi-Supervised Learning in Hasty
Many projects nowadays use large-scale datasets with thousands and millions of images. Training models on them requires many labeled examples that are expensive to annotate and acquire.
In Hasty, we want to help you reduce annotation effort and time while increasing your model’s performance. Automated labeling, Active Learning, and AI assistants serve this goal.
Semi-Supervised learning (SSL) is another feature that improves your model performance by using unlabeled data training sets more effectively. We have built it based on the Unbiased Teacher for Semi-Supervised Object Detection paper.
As the research shows, with only 1% labeled data from MS-COCO, the proposed method improves mAP 6.8 times in comparison to the state-of-the-art method, STAC (Sohn et al., 2020b). Moreover, Unbiased Teacher consistently improves mAP 10 times using only 0.5, 1, 2, and 5% of labeled data compared to the supervised approach.
You should give SSL a try if:
- You work with large datasets and would like to process them faster;
- You have a small percentage of your dataset labeled (from 1% to 10%);
- You work on Object Detection or Instance Segmentation task (other models are not supported).
How Semi-Supervised Learning works
Supervised, Unsupervised, and Semi-Supervised approaches
To understand the mechanism behind SSL in Hasty, let’s first observe other well-known ML algorithms.
In classical Supervised Learning, the model trains on the given labeled data. The shortcoming of this approach is that in real life, it is hard to find or build clean, precisely labeled datasets.
Unsupervised Learning is used when we do not know what exact outcome to expect. In this case, we allow the model to explore the underlying data structures on its own and then analyze the results. In Object Detection or Instance Segmentation tasks, however, we usually know in advance what classes we expect to distinguish. Thus, Unsupervised Learning might not be perfect here, as well.
Therefore, Semi-Supervised Learning comes into play. Essentially, it uses a combination of labeled, poorly labeled, or unlabeled data to train the model. This is more efficient than labeling everything and allows us to require the desired output from the model.
Pseudo-labeling & Teacher-Student paradigm
One common way to speed up the model’s learning is to train it on both labeled and unlabeled images simultaneously.
The workflow is the following:
- We create two separate models – a Teacher and a Student.
- The Teacher is trained on labeled images as in a regular supervised approach using Cross-entropy loss.
- Once the Teacher is trained, it creates pseudo-labels for the unlabeled images. The mechanism is simple: the Teacher predicts classes for unlabeled pictures –> the class the model is the most confident about is taken as a pseudo-label for the given image. Pseudo-labels are assigned only if the model is sure about them enough.
- The Student trains on combined labeled and unlabeled images (with pseudo-labels). Various augmentations and noise can be introduced to the images to train the model better.
- When the Student is trained, it becomes the new Teacher. The process is repeated again until a certain performance criterion is reached.
Source
Bias problem in pseudo-labeling
Object Detection and Instance Segmentation tasks have their own peculiarities which might affect the efficiency of pseudo-labeling. Here are the most common problems that appear:
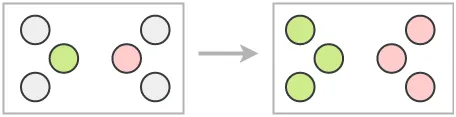
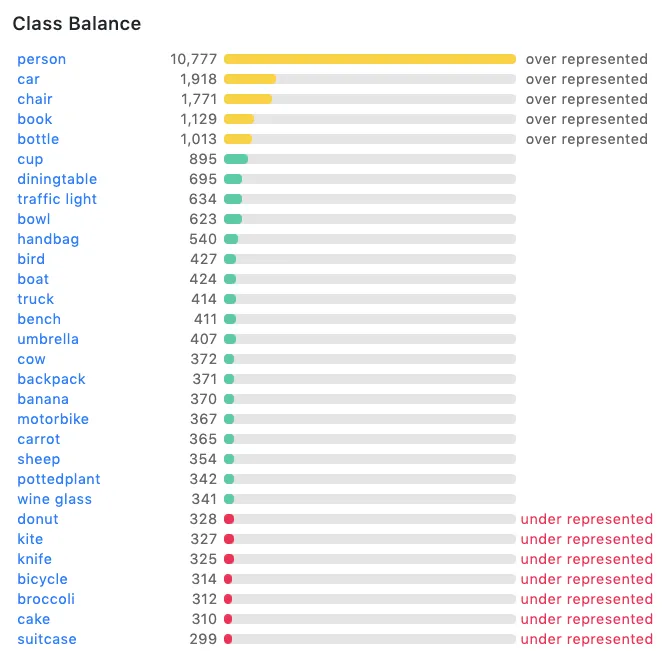
- Foreground classes imbalance: certain class(-es) might be dominant throughout the dataset, while others might be underrepresented.
- Foreground-background imbalance: the background area might be much bigger than the foreground, so most bounding boxes might get labeled as background.
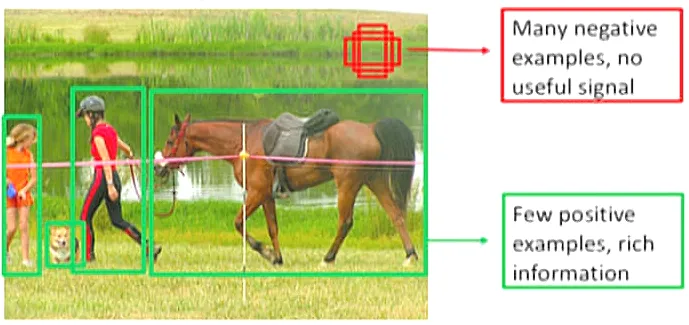
These imbalances introduce bias to the model’s predictions. The problem with pseudo-labeling is that the model might consistently lean towards the most dominant and confident classes, ignoring less represented ones. Thus, wrong pseudo-labels are created and fetched to the model, decreasing its performance.
Solution: Unbiased Teacher model
To address the problem of biased pseudo-labels, the following techniques were introduced:
- Multi-class Focal loss instead of the standard Cross-entropy loss.
- When we try to minimize Cross-entropy loss, we punish the model when it makes wrong predictions. However, the model might still get the most predictions correctly simply due to the prevalence and high confidence of some classes. As a result, the loss metric does not drop much since wrong predictions for minor classes do not affect the loss metric significantly.
- With a multi-class Focal loss, we punish the algorithm more for wrong low-confidence predictions. Thus, we prompt the model to pay more “attention” to less-represented classes and harder samples, increasing its performance. As a result, the model focuses on hard samples instead of the easier examples that are likely from dominant classes.
- Exponential Moving Average (EMA) training was added.
- EMA is a metric that measures the average value while placing greater weight on the most recent data. This approach is opposed to the Simple Moving Average (SMA), where equal weight is applied to all data points. In our case, EMA helps to update the Teacher model gradually.
- Since the Student model trains in iterations, the slowly progressing Teacher can be viewed as the ensemble of Student models in different time steps (iterations). This regularization leads to a more robust Teacher model.
The workflow behind the Hasty SSL feature
The framework we adopted is the Unbiased Teacher approach, where Student and gradually progressing Teacher help each other to progress.
The process can be divided into 2 stages:
- BurnIn stage: at this stage, we simply train the object detector using the available supervised data to get started with predictions. Usually, 100 iterations are enough at this stage.
- Teacher-Student Mutual Learning stage: we copy the initialized object detector into Teacher and Student models.
Two steps are repeated within this stage:
- Student Learning: the Teacher generates pseudo-labels to train the Student. To increase the model’s robustness, the Teacher makes predictions on weakly augmented images, and the Student is trained on strongly augmented images;
- Teacher Refinement: the Student gradually updates the Teacher using Exponential Moving Average (EMA). We can manually specify when we want to update the Teacher - in 10, 100, or 1000 iterations.
The updated Teacher generates new pseudo-labels for the next batch of images. Thus, the pseudo-labels on which the Student is trained are also refined, leading to the improvement of the Teacher, in turn.
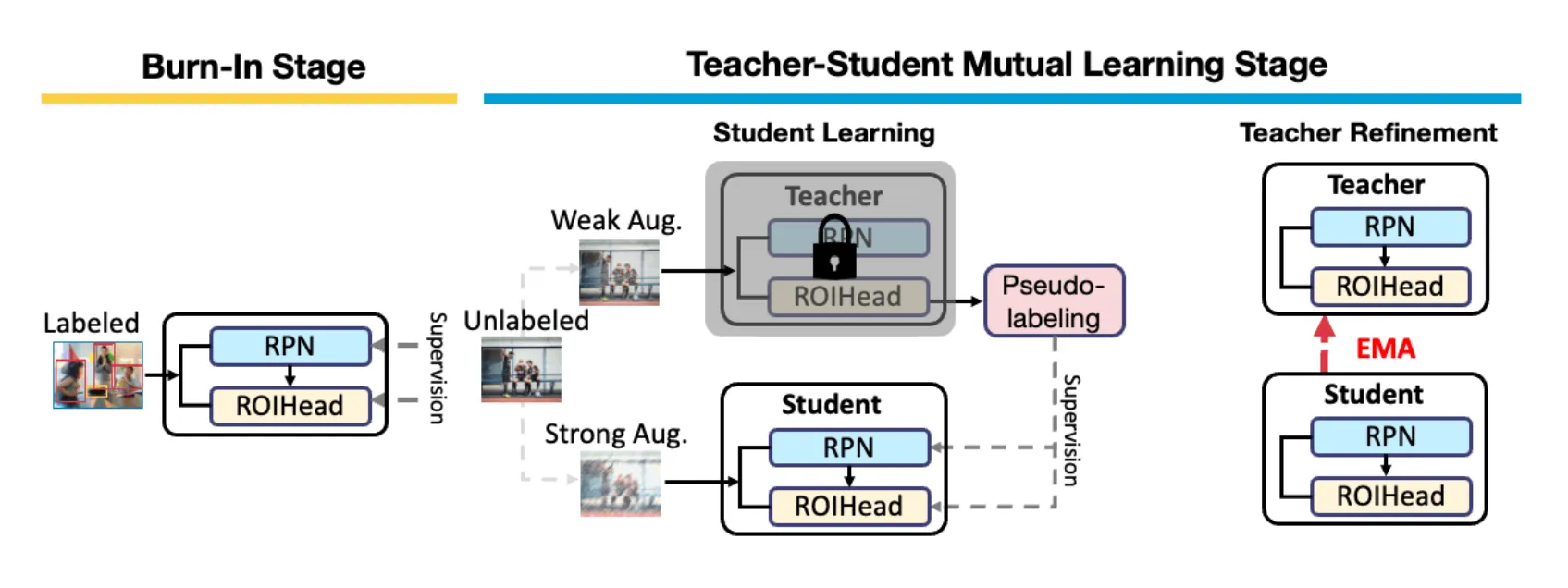
When the Teacher reaches the desired performance threshold, we take it as our final model.
When Semi-Supervised Learning is efficient
It’s hard to give rigid estimates since every dataset and every use case is unique. However, there are certain recommendations you might want to follow to squeeze the most out of the feature:
- SSL shows the most efficiency on large datasets. The more images you have, the more improvement in model performance you can expect to see.
- The most optimal use case is when around 1% of your dataset is labeled. The more images you have labeled already, the less will be the relative improvement brought by SSL. For instance, if your dataset is 50% labeled, your model will likely train quite well already, so the effect of SSL will not be that critical.
- However, if your dataset is complex, it would be better to label more than 1% to get any benefit from SSL. For example, if you work with complex medical data requiring high-level human expertise, the SSL algorithm might need more labeled input to train well on it and produce good results.
- The number of classes matters. The more classes you have, the more images you need for SSL to be effective. For example, if you need to detect 1000 classes and have a dataset of only 5k images, it might be quite tough to train a robust SSL model based on that.
On the contrary, if you have only 2-4 classes, you might require fewer images for SSL to be helpful.
How to access Semi-Supervised Learning
You can access the Semi-Supervised learning feature within Model Playground.
To do so, create a split and toggle on the “Semi-Supervised Learning” option. Thus, you will be able to include unlabeled data in your split.
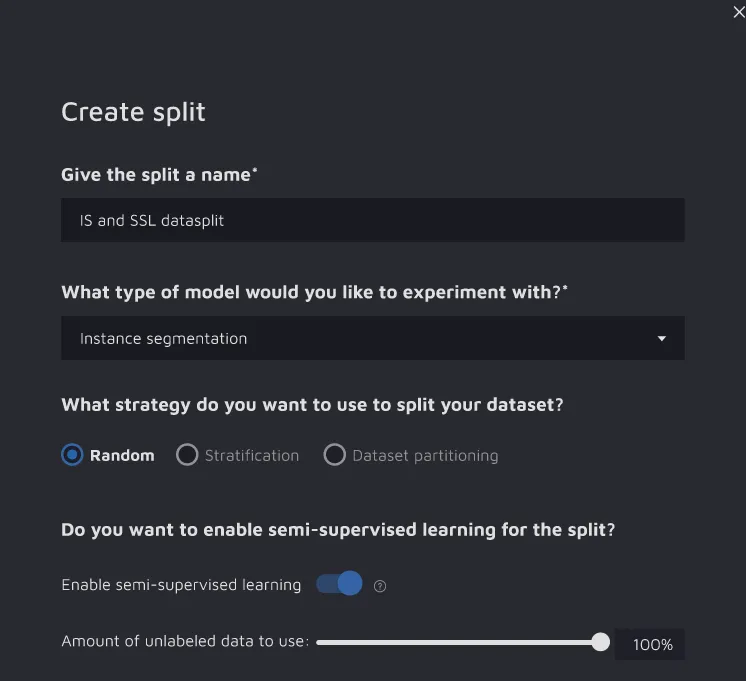
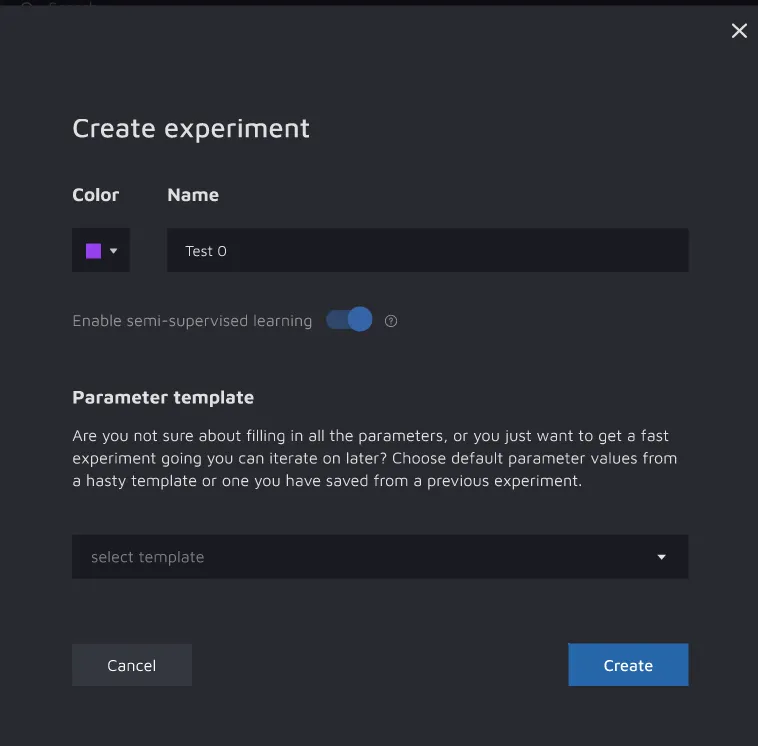
When creating new experiments, enable the SSL option as well.
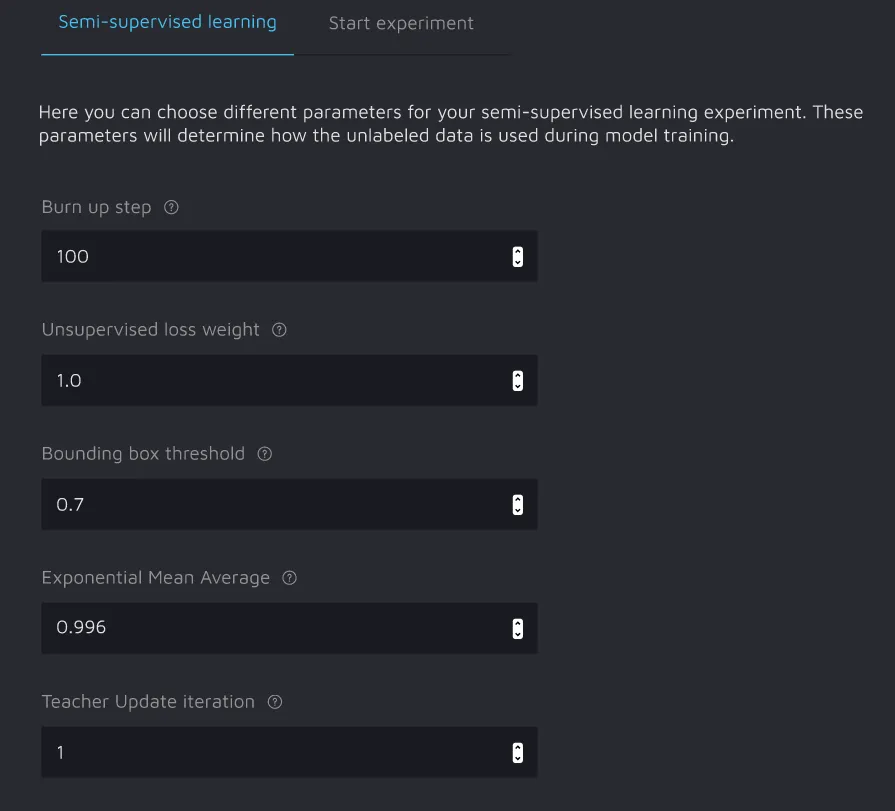
You will be able to play with the following training parameters:
- Burn up step – the number of iterations required to finish the BurnIn stage;
- Unsupervised loss weight – a coefficient by which we will multiply the loss calculated on pseudo-labels;
- Bounding Box Threshold – only pseudo-labels with confidences exceeding this threshold will be used;
- Exponential Mean Average – the number of recent iterations the average of which you want to take;
- Teacher Update iteration – the number of iterations of the Student model after which the Teacher is updated.
Please remember that SSL is available only for Object Detection and Instance Segmentation tasks.
Summary
Semi-Supervised learning helps to increase your model performance for OD/IS tasks by leveraging raw data in the dataset. It shows the best efficiency when 1% (ideally) with up to 5-10% of the images are labeled.
When used in such cases, the SSL feature can help automate your labeling up to 6-10 times.
Thanks for reading, and happy training!